# 工作流
# 工作流搭建
登录IGServer-X站点,选择左边目录工作流。在浏览器中以拖拽的形式搭建大数据工作流。通过拖拽左侧的大数据分析算子,自由组合搭建符合自己业务流程的工作流。
# 算子拖拽
展开左侧目录树,将算子或起始节点拖拽至画布,即可查看算子的输入输出参数,并进行流程搭建。
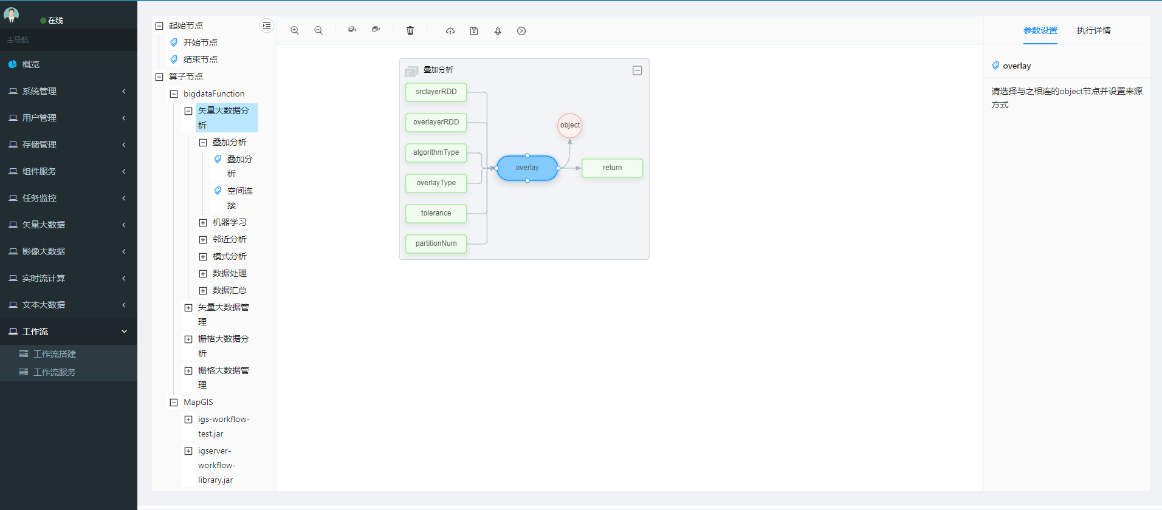
# 节点介绍
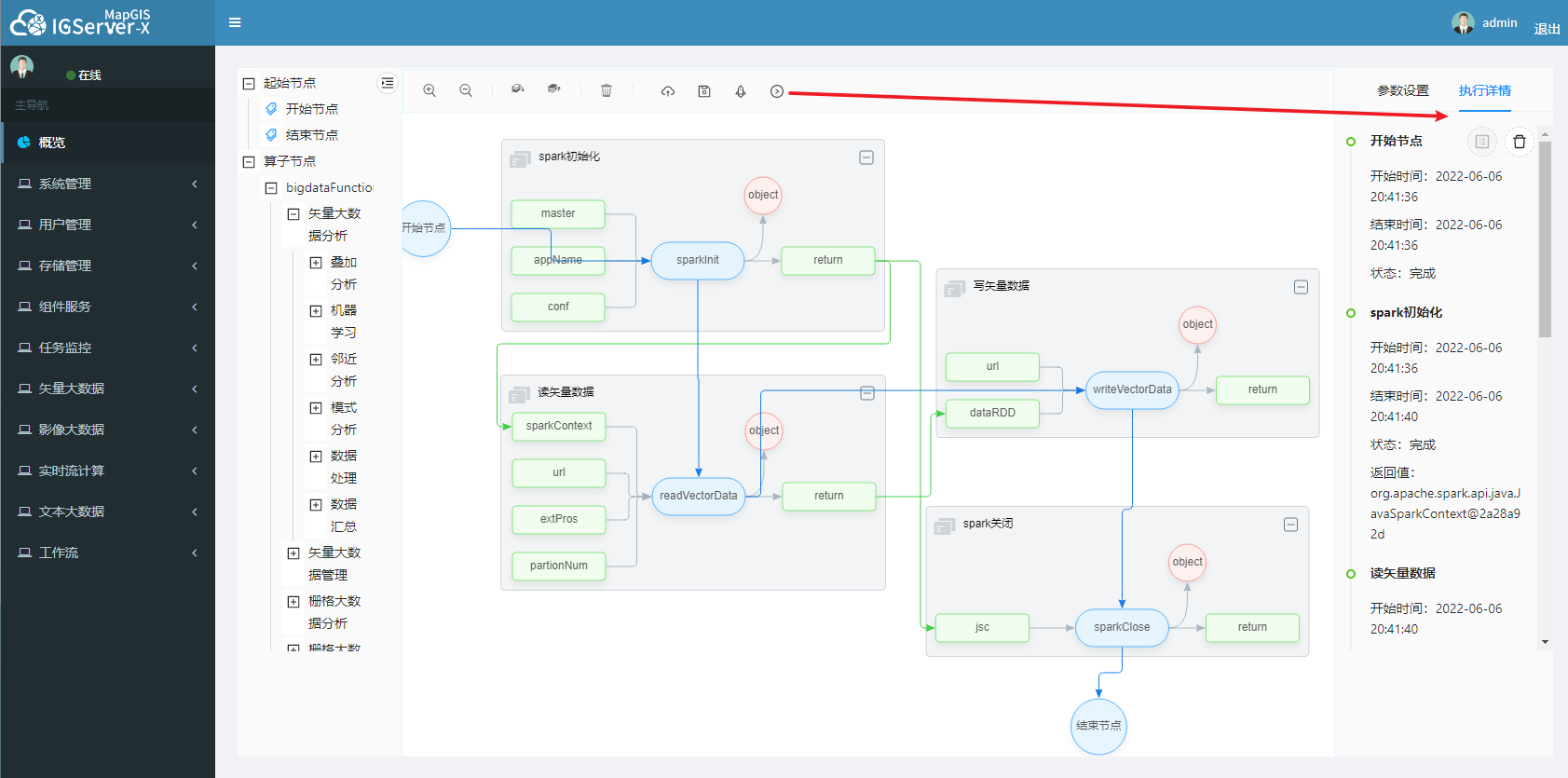
拖拽后的算子在画布上呈现出主流程节点、输入输出参数、功能对象、整体组合4个部分,以下图为例,依次介绍每一类节点:
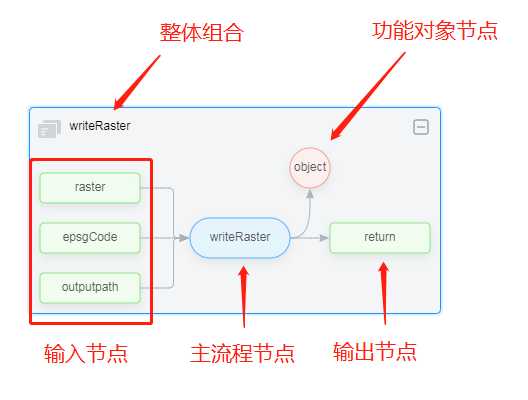
- 主流程节点
最中间椭圆矩形的节点为主流程节点,主要用作主流程的搭建。
- 输入输出参数节点
输入节点展示了该算子的所有输入参数,一般需要通过点击这些节点指定参数来源方式。输出节点常常用作其他参数或功能对象的来源。
- 功能对象节点
圆形的object节点为算子的功能对象,同样也需要点击该节点来指定来源方式。
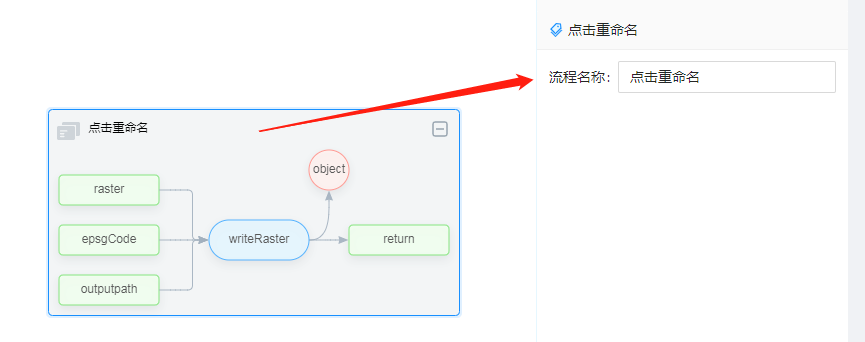
- 整体组合
组合通过矩形框对各个流程进行区分。单击矩形框,可在右侧修改流程名称,从而实现流程的重命名功能。
# 流程搭建步骤
将流程节点依次拖拽至画布上以后,即可进行流程搭建。搭建流程的步骤为连接主流程、功能对象来源方式以及输入参数来源方式的确定。
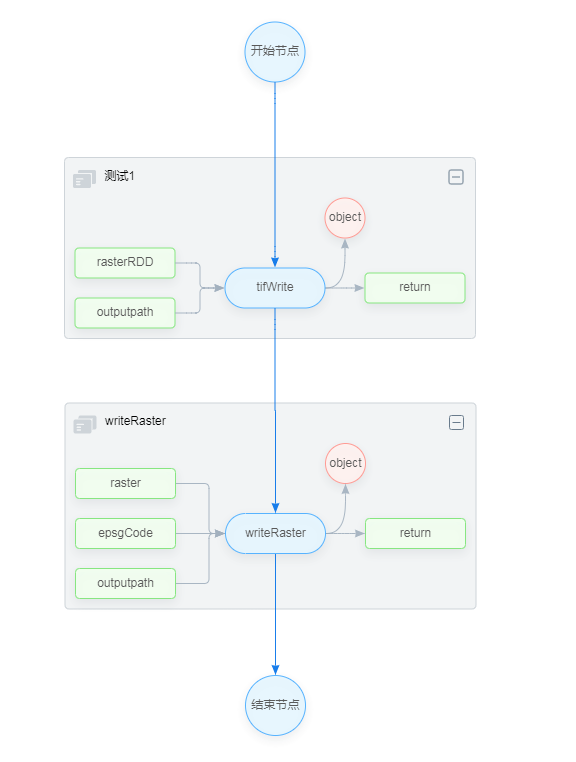
- 连接主流程
节点拖拽完毕后请优先进行主流程的连接,如下图所示:
- ‘功能对象’来源方式选择
然后按流程图顺序依次点击圆形object节点,选择功能对象来源方式。若选择指定前流程创建对象/返回值对象,则需要通过连线将前流程的object节点/return节点指向此节点。如下图所示:
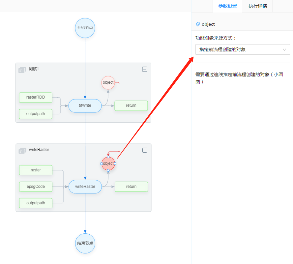
# 保存至本地
流程搭建完毕后,点击"保存"至本地,输入表单项后提交,即可将流程图xml文件保存至本地。
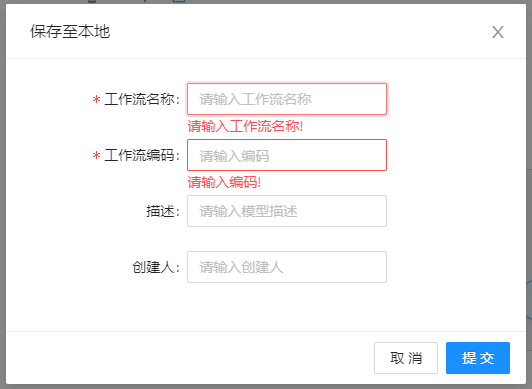
# 打开本地流程图文件
点击界面的上传按钮,选择流程图xml文件,即可将已搭建好的流程图回显在画布上。
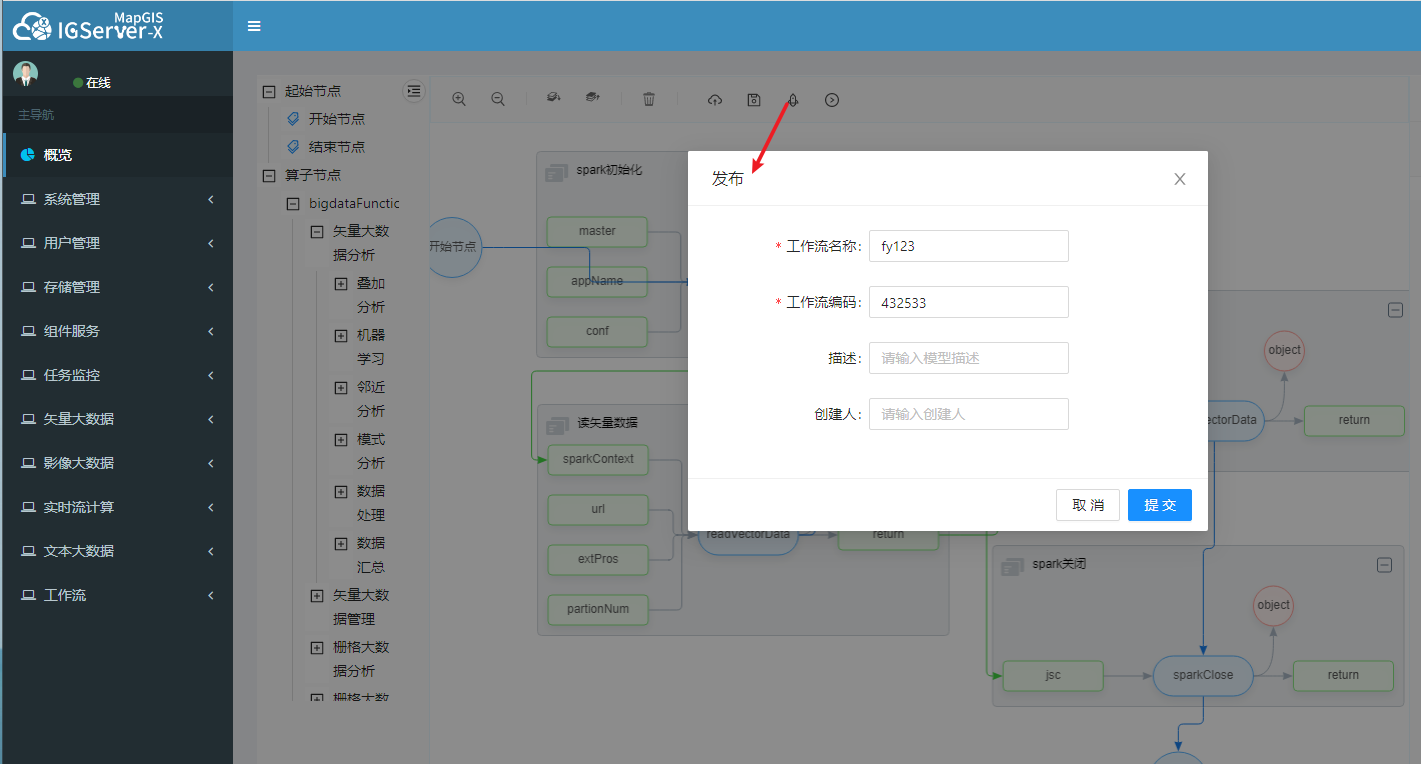
# 发布工作流
点击发布按钮,可以将工作流保存至服务器端,登录 IGServer-X 的用户皆可看见该工作流。
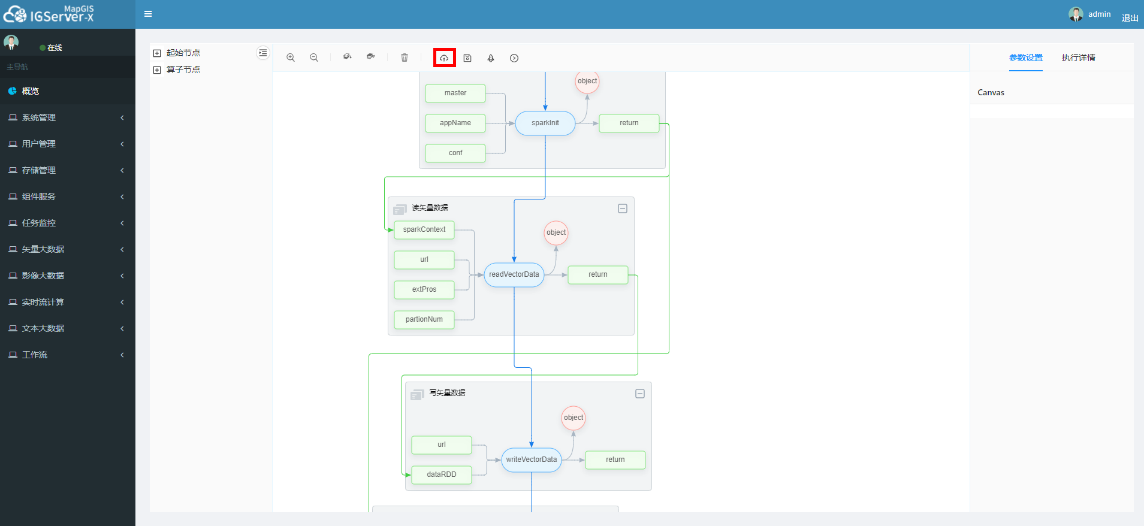
# 执行工作流
点击"执行"按钮,右侧有执行的情况。
# 注意事项
- 保存前保证所有输入参数的来源方式已填写/连线、所有功能对象来源方式已填写/连线。
- 禁止使用键盘的“ctrl+z”快捷键进行撤销操作,推荐使用delete键删除线或组合。
- 主流程的删除可以通过选择整体组合框,再点击delete的方式。
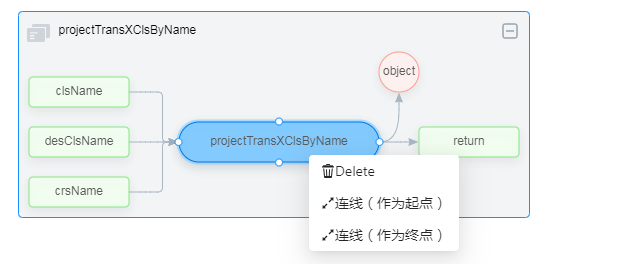
- 若出现两个待连接的节点相距太远(未能出现在同一屏幕上),可以通过右键选择“连线(作为起点/终点)”的方式先后点击两节点连接,如下图:
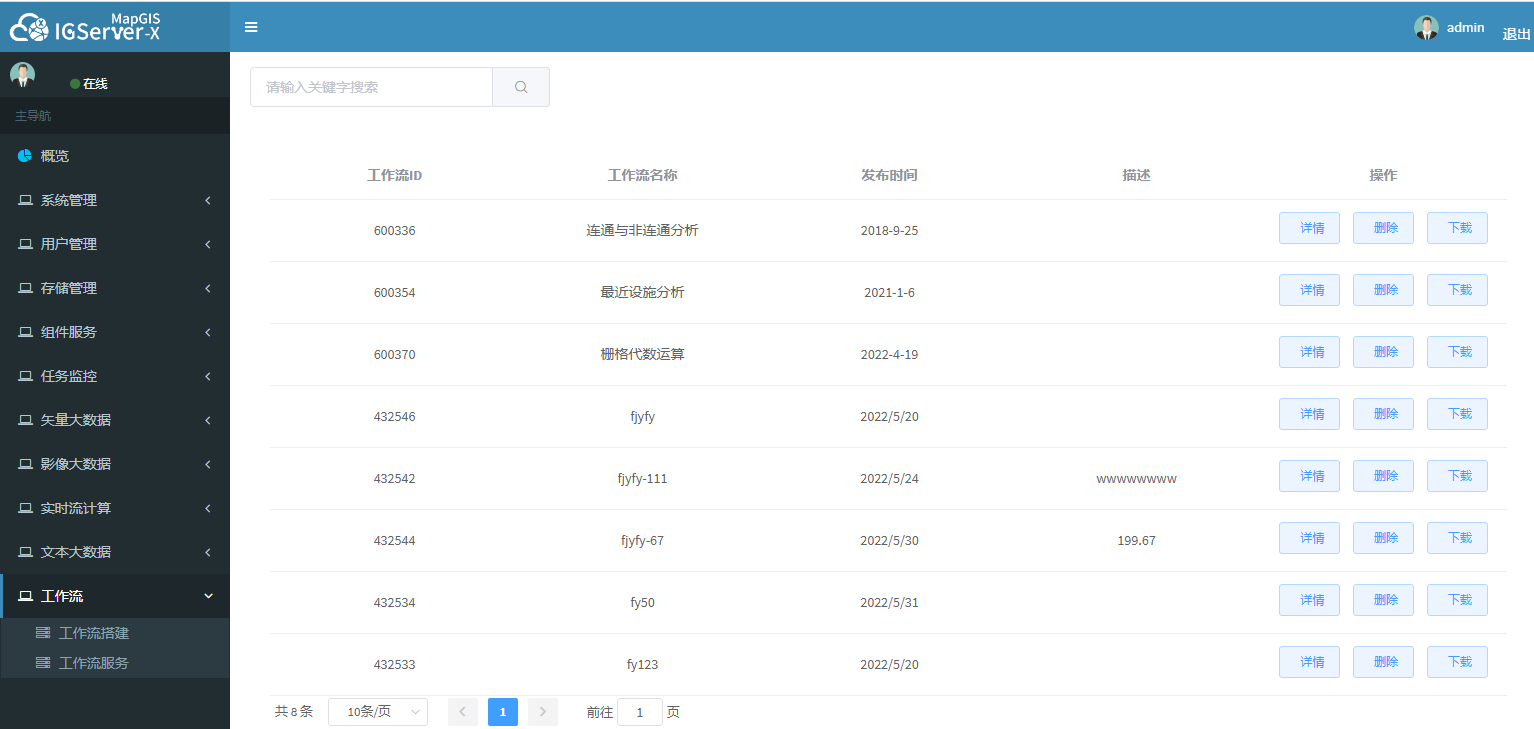
# 工作流服务
展示了已经发布的工作流服务,点击执行输入参数后可以进行工作流运算分析。
MapGIS提供了一些工作流服务示例脚本,下面将介绍部分脚本的具体使用方法:
# 网格编码
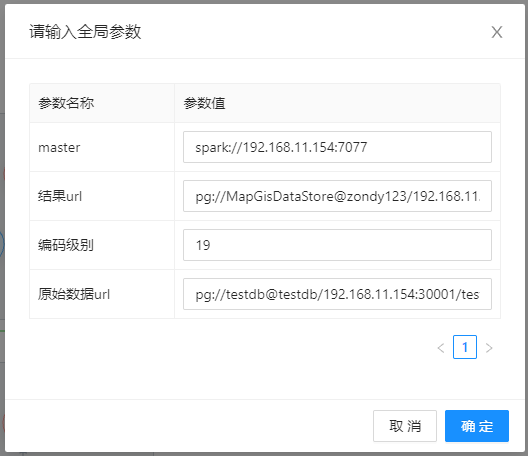
- 【master】:Spark主节点地址,以spark://协议开头的地址,如spark://192.168.11.106:7077;
- 【结果url】:存放结果数据的pg数据源路径,编码结果会在点线区要素中生成code编码属性字段,可以在DataStore中进行编码查询;
- 【编码级别】:划分点线区要素格网的级别数,级别越高格网越密,最高可为19级;
- 【原始数据url】:待编码的原始点线区要素存储路径。
# 网格剖分
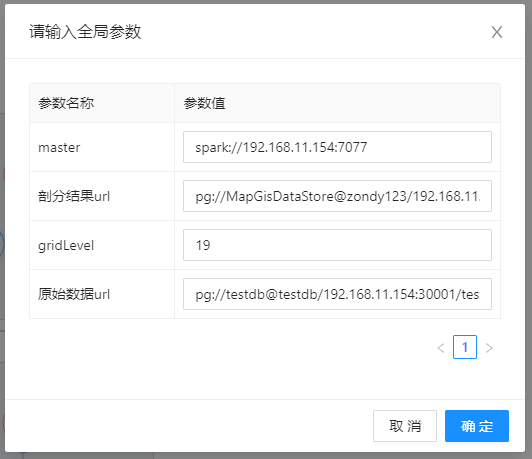
- 【master】:Spark主节点地址,以spark://协议开头的地址,如spark://192.168.11.106:7077;
- 【剖分结果url】:存放结果数据的pg数据源路径;
- 【剖分级别】:剖分点线区要素格网的级别数,级别越高格网越密,最高可为19级;
- 【原始数据url】:待剖分的原始点线区要素存储路径。
# 网格剖分-聚合
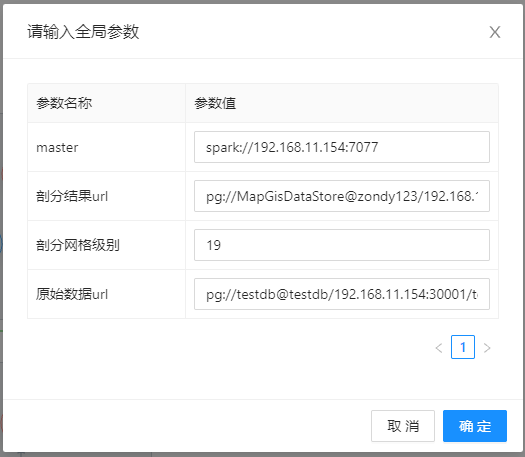
- 【master】:Spark主节点地址,以spark://协议开头的地址,如spark://192.168.11.106:7077;
- 【剖分结果url】:存放结果数据的pg数据源路径;
- 【剖分级别】:聚合剖分点线区要素格网的级别数,级别越高格网越密,最高可为19级;
- 【原始数据url】:待剖分的原始点线区要素存储路径。
# 管网漏损预测
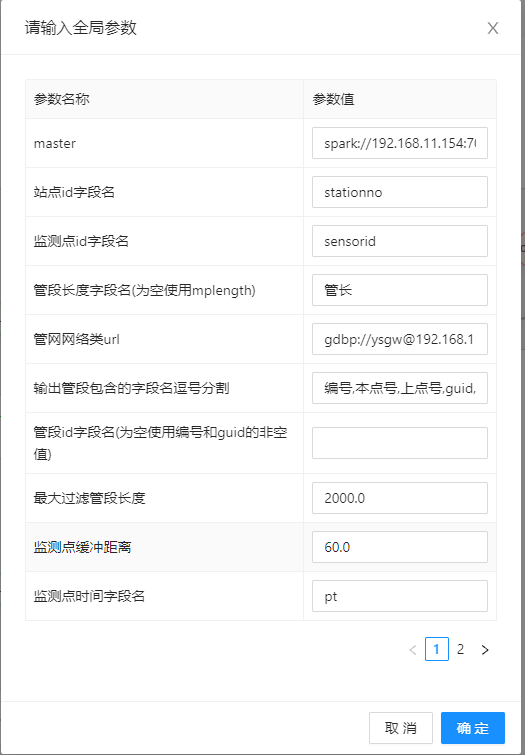
【管网网络类url】:在MapGIS Desktop产品中连接准备好的数据源,右键网络类要素选择复制URL,粘贴在此处。
提示:
当MapGIS Datastore无法直接在界面层访问网络数据源中的数据时,需要先在IGServer -X环境中配置该数据源:
1、定位到/MapGISIGServerX/lib/MapGIS10/program目录下;
2、配置环境变量;
3、执行添加数据源命令行:./tool_datasource -O 3 -P 21 {ip}:{port}/{数据库名} {数据源名称};
添加pg数据源示例命令行如下:
#cd /MapGISIGServerX/lib/MapGIS10/program/ #export LD_LIBRARY_PATH=$(pwd):$LD_LIBRARY_PATH #echo $LD_LIBRARY_PATH #./tool_datasource -O 3 -P 21 192.168.11.106:36001/test 192.168.11.10636001test
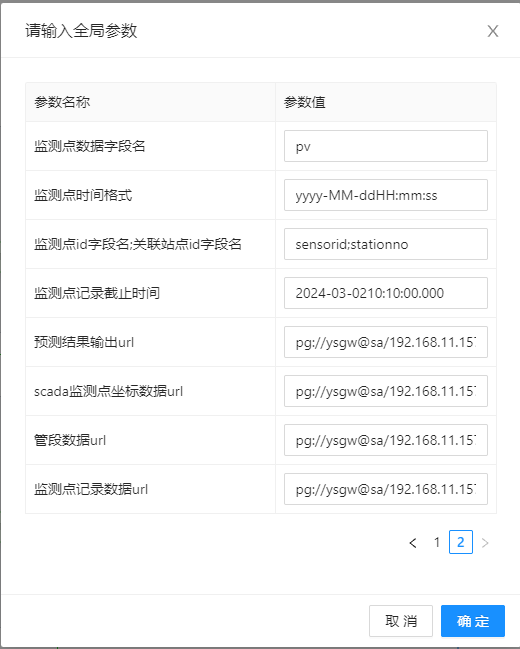
- 【数据url】:分别填写各类数据存放路径。
# 管段健康状态评估-训练
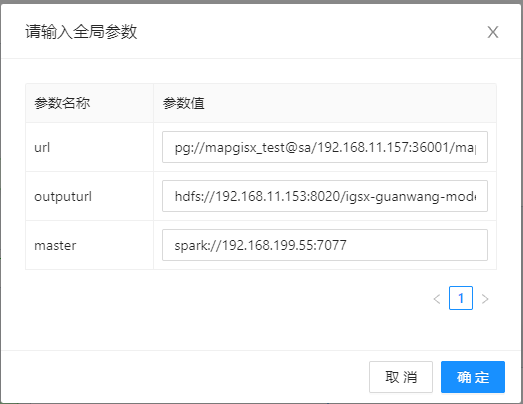
- 【url】:填写管段的pg数据源路径;
- 【outputurl】:填写保存输出结果的路径,一般存放于hdfs中;
- 【master】:Spark主节点地址,以spark://协议开头的地址,如spark://192.168.11.106:7077。
# 管段健康状态评估-预测
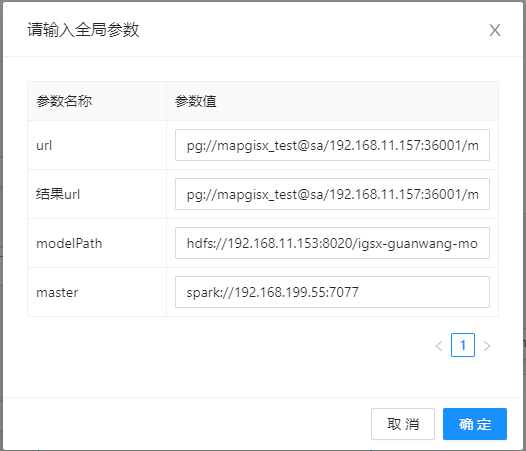
- 【url】:填写管段的pg数据源路径;
- 【结果url】:填写保存输出结果的路径;
- 【modelPath】:填写“管段健康状态评估-训练”中的输出结果路径;
- 【master】:Spark主节点地址,以spark://协议开头的地址,如spark://192.168.11.106:7077。
← 文本大数据