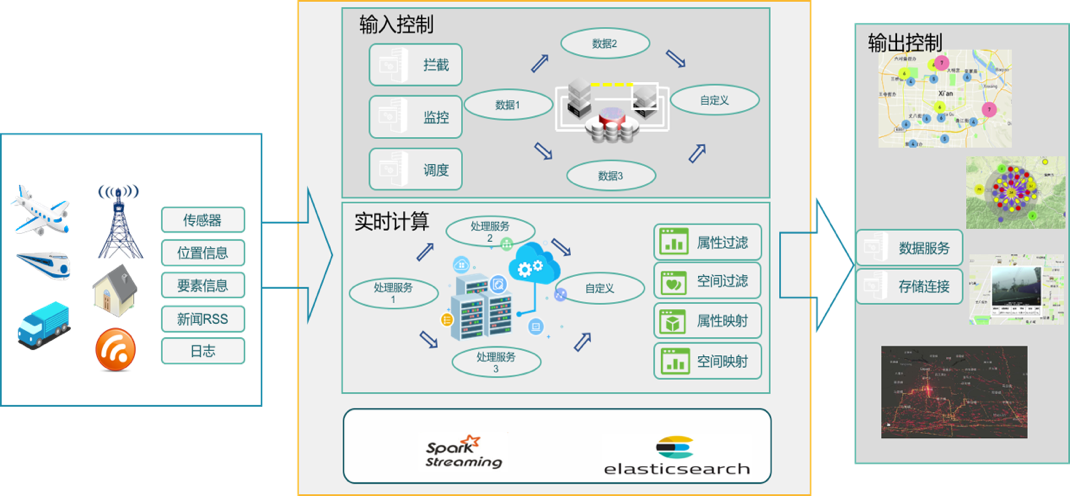
# 实时流计算
实时数据具备顺序、快速、大量、持续到达等特点,在应用中需要及时完成查询、分析和展示。基于Spark Streaming的实时大数据计算,通过将实时数据与Spark Streaming实时流计算框架深度融合,通过ElasticSearch数据库实现每秒成千上万条实时数据记录的写入与高效的查询,提供实时大数据的接收、处理与分析服务。
实时大数据计算服务支持多种数据传输协议,能够高效接入物联网,车联网各种传感器产生的实时数据,提供流数据汇聚、时空归一化、地理围栏等多种时空大数据服务。
# 相关工具使用说明
# Kafka消息队列常用命令
# 创建队列
1. 进入MapGIS IGServer-X安装目录下,如.../MapGISIGServerX/sources/kafka_2.11-1.1.1/bin;
2. 在终端执行sh kafka-topics.sh --create --topic streamdemo --partitions 1 -replication-factor 1 --zookeeper 127.0.0.1:16181命令,创建一个新的队列,根据配置修改kafka中zookeeper的ip和端口等配置,如图所示:

3. 配置参数说明
| 配置参数 | 说明 |
|---|---|
| --topic | 队列名 |
| --partitions | 分区数,可以给1,也可根据实际情况给对应值 |
| --replication-factor | 备份数,可以给1,也可根据实际情况给对应值 |
| --zookeeper | 协调服务的地址信息,根据配置给定 |
# 查看队列
1. 进入MapGIS IGServer-X安装目录 .../MapGISIGServerX/sources/kafka_2.11-1.1.1/bin;
2. 在终端执行sh kafka-topic.sh list –zookeeper 127.0.0.1:16181命令,查看已经存在的消息队列列表,如图所示:

# 删除队列
1. 进入MapGIS IGServer-X安装目录 …/MapGISIGServerX/sources/kafka_2.11-1.1.1/bin;
2. 在终端执行sh kafka-topics.sh --delete --topic streamdemo zhc --zookeeper 127.0.0.1:16181命令,删除一个已经存在的队列,如图所示:

# 控制台使用生产者
1. 进入MapGIS IGServer-X安装目录 .../MapGISIGServerX/sources/kafka_2.11-1.1.1/bin;
2. 在终端执行sh kafka-console-producer.sh --topic streamdemo --broker-list 192.168.80.104:9092命令,程序会一直等待,可输入字符,然后按Enter键发送,如图所示,:

# 控制台使用消费者
1. 进入MapGIS IGServer-X安装目录 .../MapGISIGServerX/sources/kafka_2.11-1.1.1/bin;
2. 在终端执行sh kafka-console-consumer.sh --topic streamdemo --zookeeper 127.0.0.1:16181 –from-beginning命令,启动消费者,程序会一直等待,有数据的时候,会输出到控制台,如图所示:

# 启动kafka数据发送模拟器
1. 进入MapGIS IGServer-X安装目录 .../MapGISIGServerX/tools/simulator_kafka/config;
2. 打开producer.properties文件,编辑配置项,主要编辑kafka服务地址和消息队列名称,如图所示,:
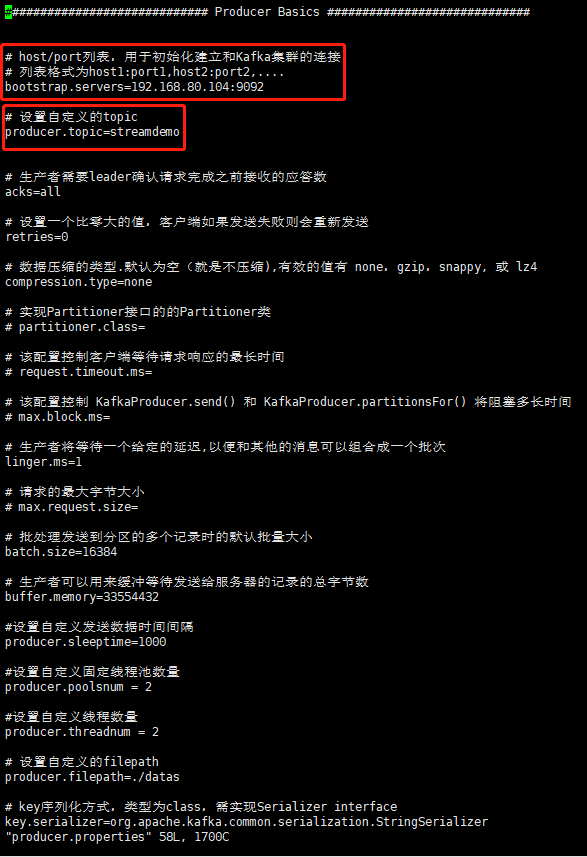
3. 进入MapGIS IGServer-X安装目录 .../MapGISIGServerX/tools/simulator_kafka;
4. 在终端执行sh start-simulator.sh命令,启动模拟发送数据的程序,程序会直接运行,如需关闭程序,请在终端执行ctrl+c,如图所示,:

5. 可在另一终端输入控制台使用消费者命令检验是否接收数据成功;
# 流计算服务定义
服务定义是用于配置流计算服务功能的json文件,对计算任务步骤的定义,包含输入连接器、输出连接器、处理器、过滤器等功能计算步骤,通过解析json文件,能得到详细的执行步骤,从而执行流计算任务。具体格式如下说明,可通过手动编辑文件生成,亦可通过界面工具(详见"流计算服务构建"工具章节)生成,示例可参考安装路径下"$HOME/MapGISIGServer-X/tools/流计算服务定义示例"目录下的json文件中内容。
格式详解如下,目前支持的输入、输出、处理器详情参考附录章节:
整个为json,字段内容如下
{
"nodes": {//流程节点列表
"kafkaInputController": {//节点
"caption": "kafka输入",//简要描述
"className": "com.zondy.streaming.pipeline.spark.kafkaInputController",//类名
"description": "kafka输入控制器",//详细描述
"format": {//输入数据源格式,只有输入控制器才有
"className": "com.zondy.mbds.pipeline.formatter.JsonFormatter",//类名
"name": "json"//格式名称
},
"name": "kafkaInputController",//节点名称
"nextNodes": ["ProjectTransformProcessor"],//下一个节点列表
"params": { //该节点参数列表Key-Values
"kafka.input.bootstrapServers": "192.168.91.125:9092",
"kafka.input.subscribeType": "subscribe",
"kafka.input.topics": "geo3ds_zhdkcs_gcbzjb02_view",
}
},
"ProjectTransformProcessor": {//节点
"caption": "投影变换",
"className": "com.zondy.streaming.processor.ProjectTransformProcessor",
"description": "投影变换处理器",
"name": "ProjectTransformProcessor",
"nextNodes": ["EsOutputController"],
"params": {
"projectTransform.processor.srcProj": "epsg:3857",
"projectTransform.processor.destProj": "epsg:4326"
},
"preNodes": ["kafkaInputController"]//前续节点列表
},
"EsOutputController": {
"caption": "es输出",
"className": "com.zondy.streaming.pipeline.spark.EsOutputController",
"description": "es输出控制器",
"format": {
"className": "com.zondy.mbds.pipeline.formatter.GeoJsonFormatter",
"name": "json"
},
"name": "EsOutputController",
"params": {
"es.output.clusterName": "cxcentor",
"es.output.esNodes": "192.168.96.101",
"es.output.esPort": "9300",
"es.output.indexName": "geo3ds_zhdkcs_gcbzjb02_view",
"es.output.indexType": "时空库",
"es.output.isAppend": false
},
"preNodes": ["ProjectTransformProcessor"]
}
},
"schema": {//其他描述
"schema": {
"fields": [{//字段列表
"name": "pkiaa",//字段名
"type": "STRING"//字段类型
},
{
"name": "hjsqha",
"type": "STRING"
},
{
"name": "pkigj",
"type": "STRING"
}
]
},
"name": "GCBZJB02_VIEW",
"geometry": {//几何字段描述
"type": "Point",
"fields": [{
"name": "tkcaf",
"formats": ["x"]
},
{
"name": "tkcag",
"formats": ["y"]
}]
},
"attribute": {//其他扩展属性
"type": "oracle",
"extAttrs": {
}
},
"time": {//时间字段信息
"fields": []
}
},
"version": "0.1"//版本
}
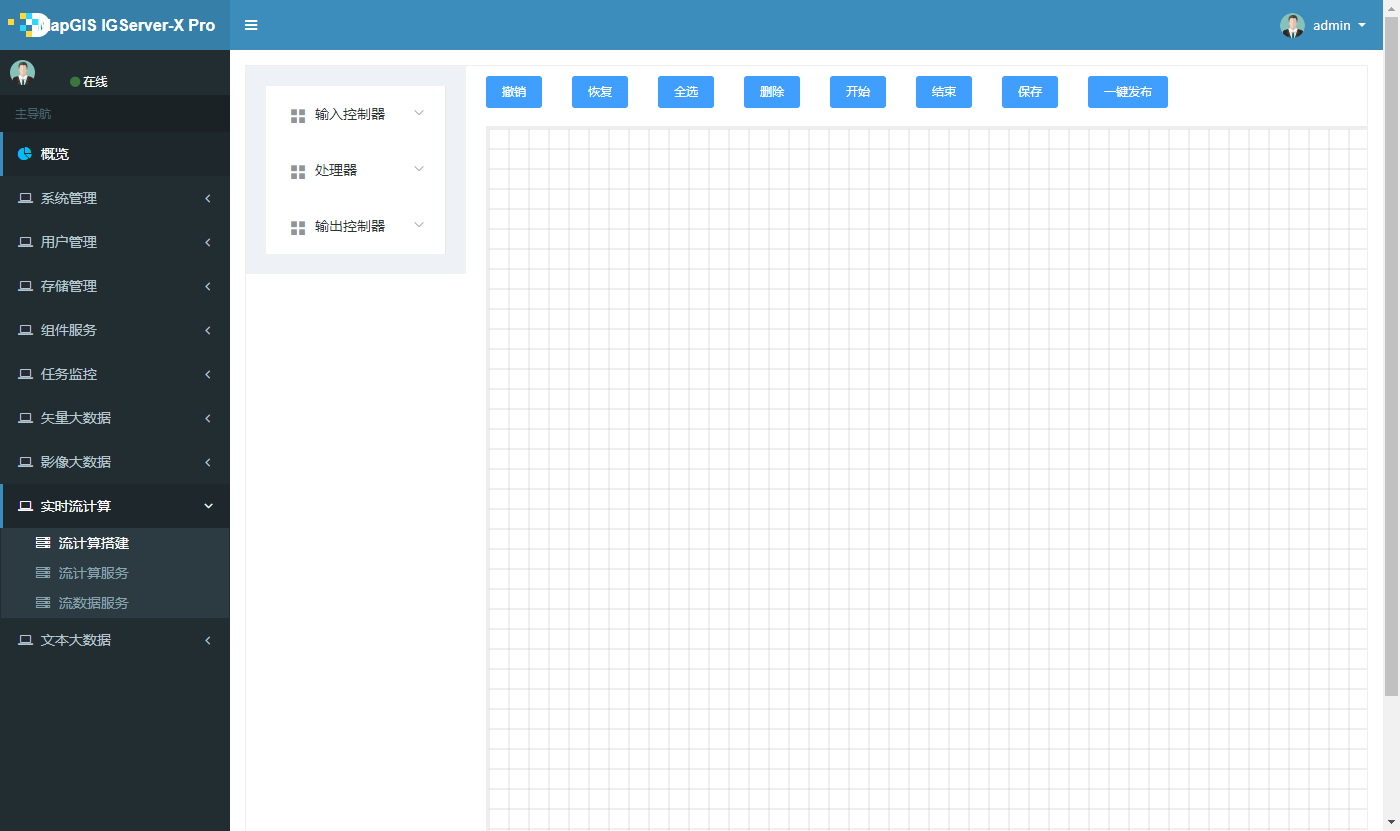
# 流计算服务搭建
# 基本流程搭建
1. 登录MapGIS IGServer-X web管理站点,点击流计算搭建,进入流计算搭建界面,如图所示,:
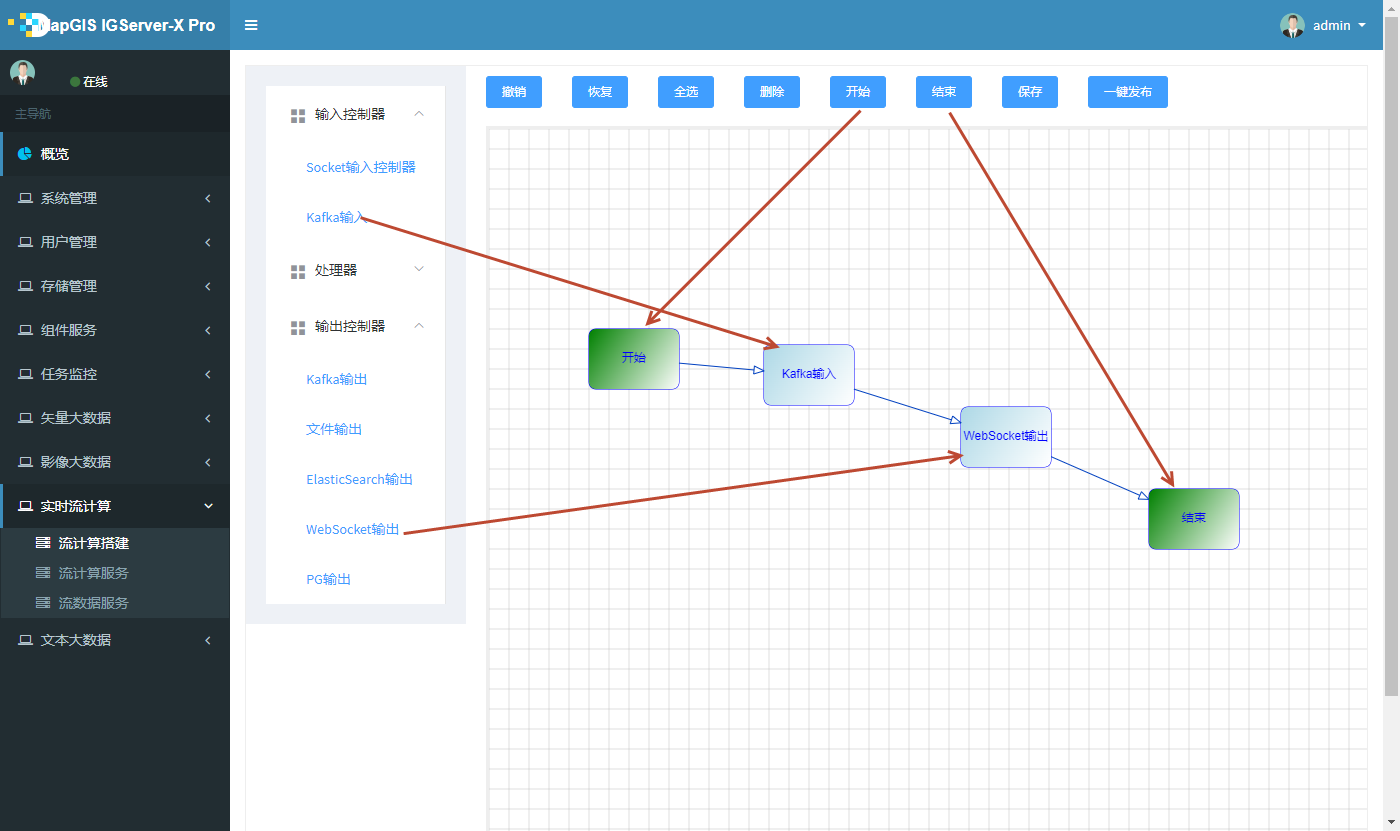
2. 一个基本的流程,至少要包括开始-输入-输出-结束四个部分;点击开始组件,依次从左侧目录树拖动输入、输出组件、点击结束组件、最后使用节点连线将所有组件按执行顺序连接起来,形成工作流,如图所示,:
提示:
持单链路模式,暂不支持分支或闭环。
# 输入控制器
# Socket输入
1. 双击Socket输入控制器弹出参数配置界面,如图所示:
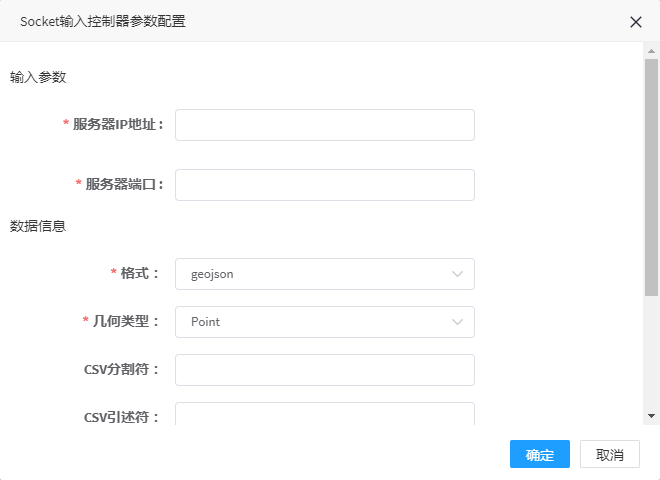
2. 参数填写说明:
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 服务器ip地址 | 是 | Socket服务器地址 |
| 服务器端口 | 是 | Socket服务器端口号,默认9999 |
# Kafka输入
1. 双击kafka输入控制器弹出参数配置界面,如图所示:
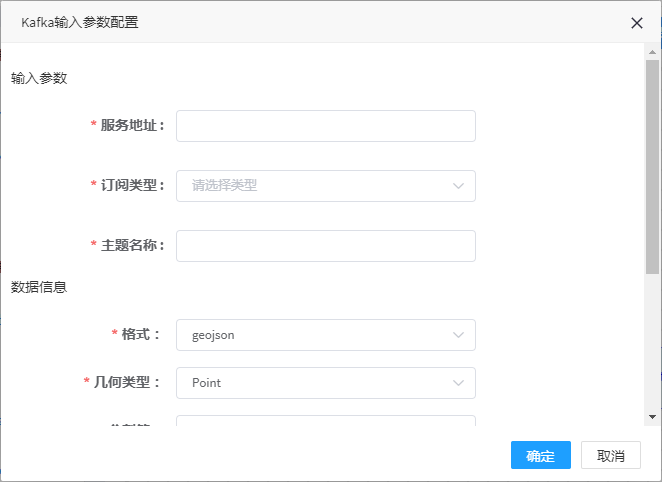
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 服务地址 | 是 | 消息队列的服务地址,含IP和端口;如192.168.80.104:9092 |
| 订阅类型 | 是 | 订阅类型,固定为subscribe |
| 主题名称 | 是 | 消息队列的队列名称;如streamdemo |
# 处理器
# 投影变换
1. 双击投影变换处理器,可弹出参数配置界面,如图所示,:
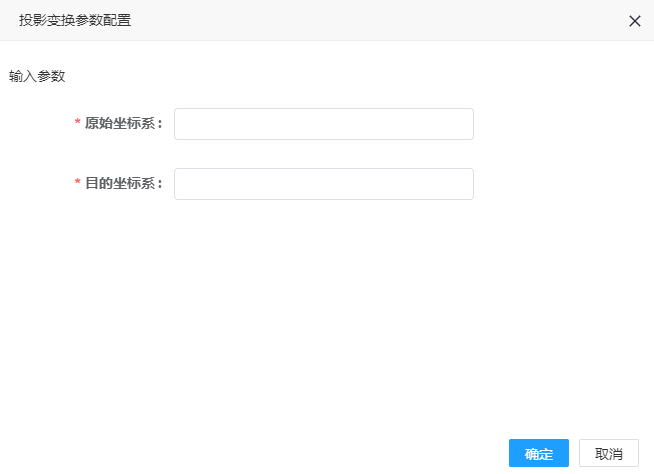
2. 参数填写说明:
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 原始坐标系 | 是 | 原始数据EPSG格式坐标,格式为EPSG:xxxx;如EPSG:4326 |
| 目的坐标系 | 是 | 目的数据EPSG格式坐标,格式为EPSG:xxxx;如EPSG:3857 |
# 属性过滤
1. 双击属性过滤处理器,可弹出参数配置界面,如图所示,:
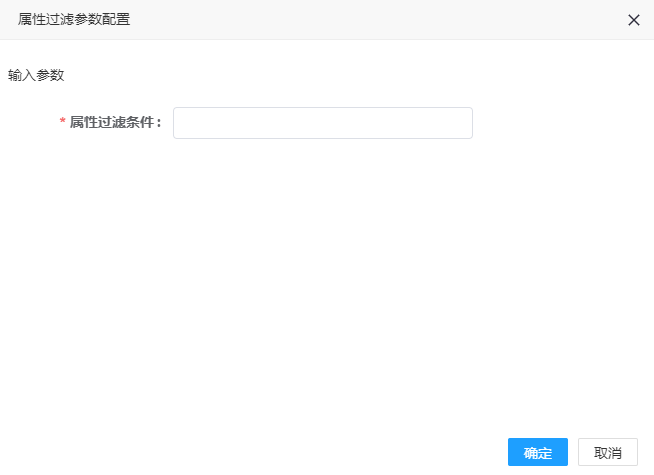
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 属性过滤条件 | 是 | 属性过滤条件,以sql表达式的形式编写,如speed>0 and speed<50 |
# 空间过滤
1. 双击空间过滤处理器,可弹出参数配置界面,如图所示,:
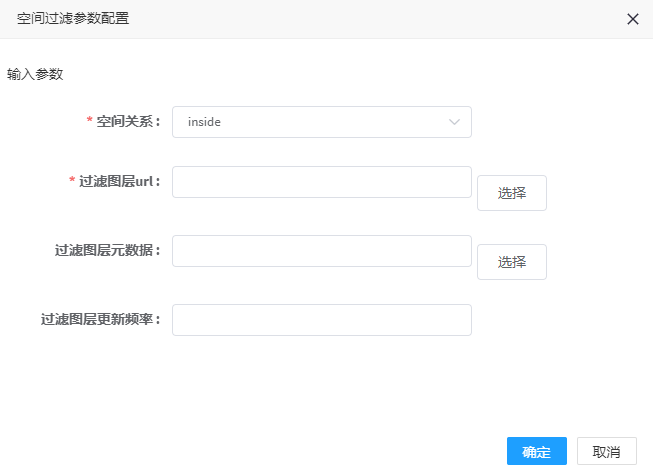
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 空间关系 | 是 | 源数据落在过滤图层内部:inside;源数据落在过滤图层外部:outside |
| 过滤图层url | 是 | 过滤图层的url地址,目前支持pg数据源 |
| 过滤图层源数据 | 否 | 过滤图层的元数据描述json文件地址,支持hdfs/file/http协议 |
| 更新间隔 | 否 | 系统内部会对过滤图层进行缓存,默认0,即不更新,设置后会定时更新缓存,保持条件的一致性,单位为秒;如60 |
# 缓冲处理
1. 双击缓冲处理处理器,可弹出参数配置界面,如图所示,:
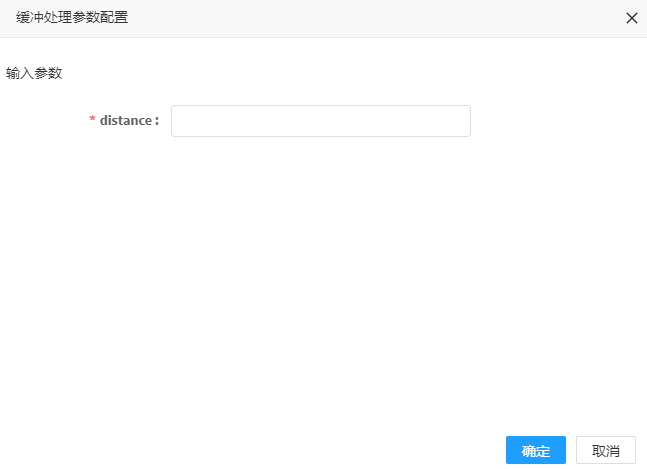
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| distance | 是 | 缓冲半径;如:0.0001 |
# 计算字段处理
1. 点击计算字段处理器,可弹出参数配置界面,如图所示,:

2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 新字段名 | 是 | 新字段类型列表,如有多个可用逗号隔开,如Fld1,fld2;字段只能由字母数字下划线组成,字母开头; |
| 新字段类型 | 是 | 新字段类型列表,用逗号分隔,个数需一致;如DOUBLE,STRING |
| 新字段表达式 | 是 | 字段表达式列表,用逗号分隔,个数需一致;如speed*2+1,10 |
# 字段映射处理
1. 点击字段映射处理器,可弹出参数配置界面,如图所示,:
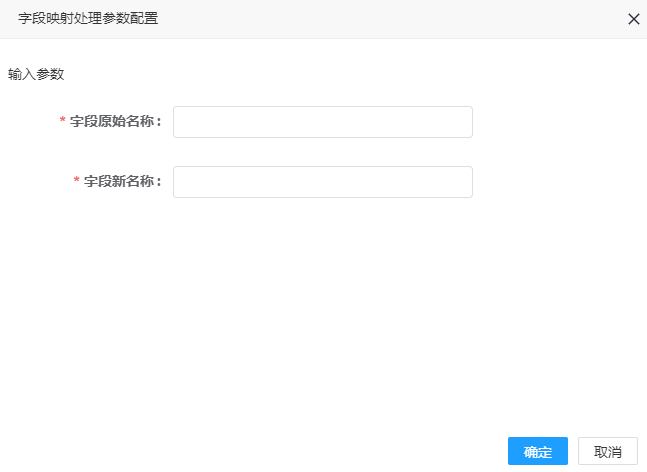
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 字段原始名称 | 是 | 字段原始名称,如有多个用逗号分隔;如fldadd02,speed |
| 字段新名称 | 是 | 字段新名称,如有多个用逗号分隔;如fldadd02map,speedmap |
# 字段删除
1. 点击字段映射处理器,可弹出参数配置界面,如图所示,:
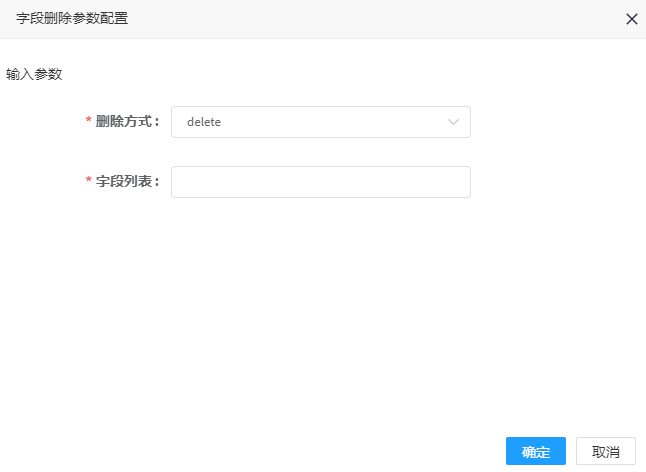
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 删除方式 | 是 | Delete:删除字段;hold:保留字段 |
| 字段列表 | 是 | 删除或保留的字段列表;如speed;如有多个请用逗号分隔 |
# 通过X,Y构造点
1. 点击通过X,Y构造点处理器,可弹出参数配置界面,如图所示,:

2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| X | 是 | X字段名 |
| Y | 是 | Y字段名 |
# SelectSQL处理器
1. 点击SQL处理器,可弹出参数配置界面,如图所示,:
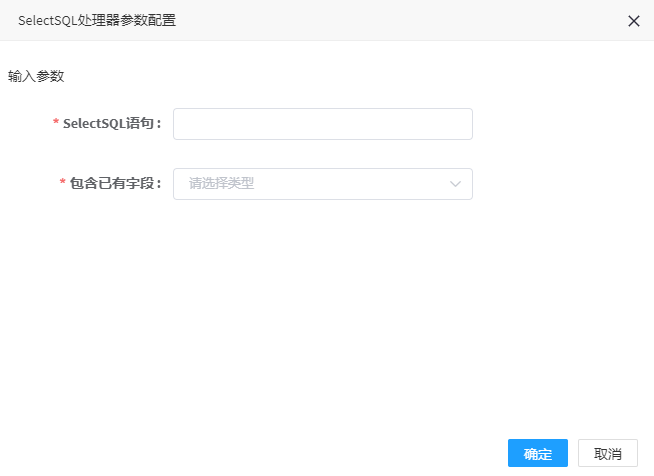
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| SelectSQL | 是 | 说明:SQL语句的Select部分的字段列表,String数组的json格式 示例:["substring(imei,9,length(imei)-1) as imei1", "`获取时间` as DataTime", "imei"] |
| 包含已有字段 | 是 | true、false |
# 输出控制器
# Kafka输出
1. 点击kafka输出控制器,可弹出参数配置界面,如图所示,:
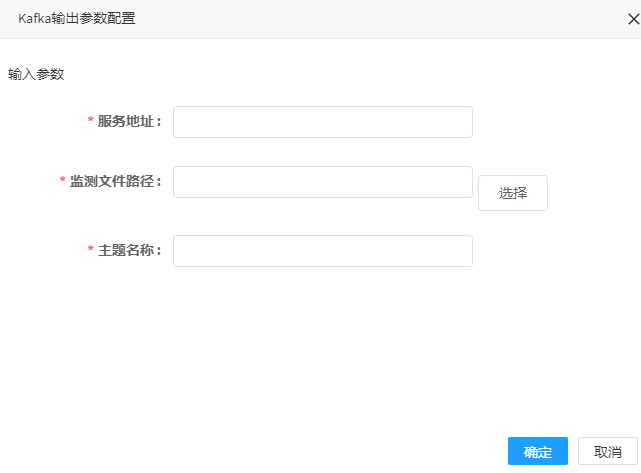
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 服务地址 | 是 | 消息队列服务地址;如:192.168.80.104:9092 |
| 监测文件路径 | 是 | 数据监测路径,运行时的临时文件,建议选择HDFS的路径(支持hdfs://,http://协议),服务器本地路径仅限于单机测试 |
| 主题名称 | 是 | 消息队列队列名称;如:streamdemo |
# 文件输出
1. 点击文件输出控制器,可弹出参数配置界面,如图所示,:
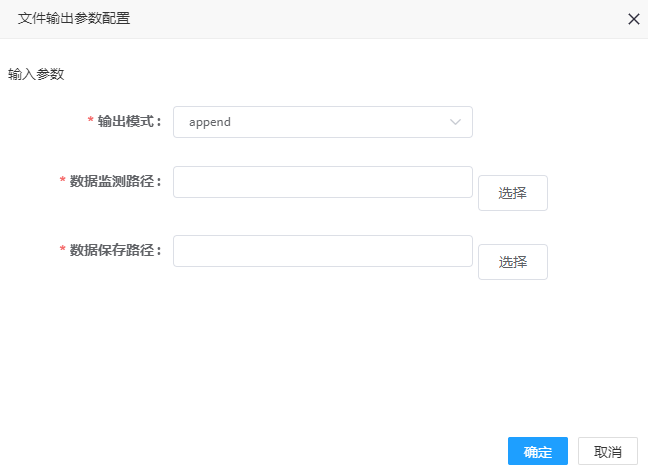
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 输出模式 | 是 | 输出模式,默认append |
| 数据监测路径 | 是 | 数据监测路径,运行时的临时文件,建议选择HDFS的路径(支持hdfs://,http://协议),服务器本地路径仅限于单机测试 |
| 数据保存路径 | 是 | 数据保存的路径,建议选择HDFS的路径(支持hdfs://,http://协议),服务器本地路径仅限于单机测试 |
# ElasticSearch输出
1. 点击ElasticSearch输出控制器,可弹出参数配置界面,如图所示,:
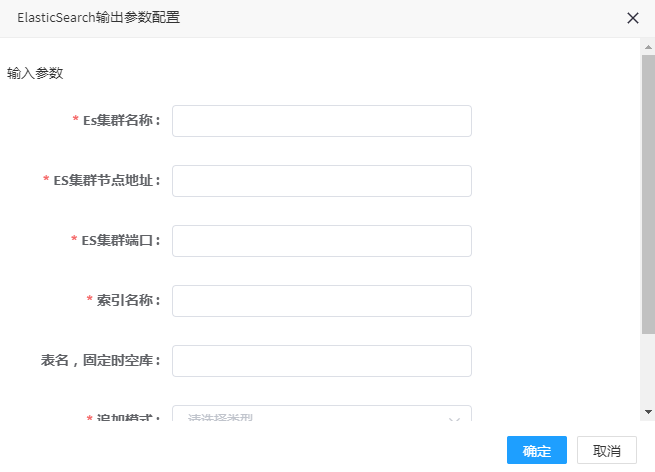
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| ES集群名称 | 是 | ES集群名称,如:clustername |
| ES集群节点地址 | 是 | ES节点机器ip地址,如:192.168.80.104 |
| ES集群端口 | 是 | ES集群端口号,默认9300 |
| 索引名称 | 是 | 索引名称,即在ES中新建时空库的名称,如:demo |
| 表名,固定时空库 | 是 | 表名,默认为DataStore中的"时空库";如:时空库 |
| 追加模式 | 是 | 是否追加模式,ture是,false否 |
| 批量大小 | 否 | 系统采用缓存,批量提交方式提升大数据量下的性能,如:10000 |
# WebSoket输出
1. 点击WebSoket输出控制器,可弹出参数配置界面
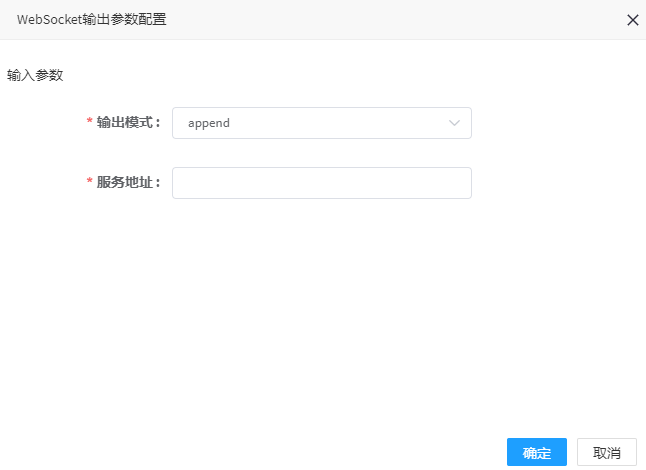
2. 参数填写说明
| 参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 输出模式 | 是 | 输出模式,默认append |
| 服务地址 | 是 | WebSocket数据发布服务地址,如:ws://192.168.91.121:9382/dataflow/streamdemo/broadcast? (可参见流数据广播地址) |
# PG输出
1. 点击PG输出控制器,可弹出参数配置界面,如图所示,:
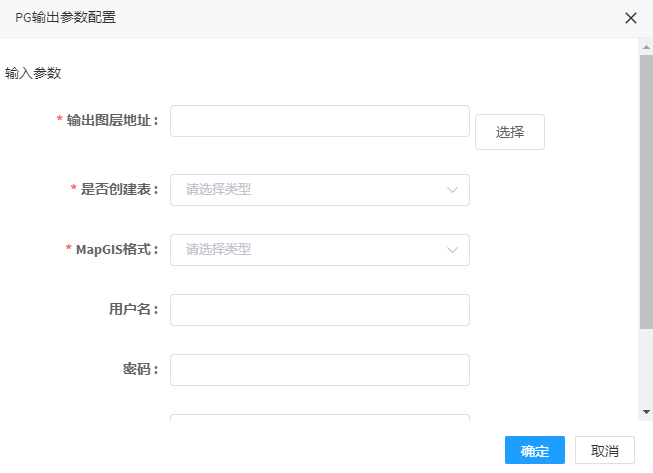
2. 参数填写说明
参数名称 | 是否必填 | 填写说明 |
|---|---|---|
| 输出图层地址 | 是 | 输出图层地址 1、DataStore配置的pg环境,可通过界面选择,得到如下内如:http://192.168.80.104:9091/datastore/rest/dataset/pg/service/sample/sample/pgoutput20190801135707 (输出文件名自动生成,也可自定义命名) 2、若使用外部的pg环境,则按此格式填: url format: [pg://userName@passWord/192.168.81.223:5432/dbName/[schema.]tableName] 如: pg://mapgis@mapgis/192.168.81.223:5432/postgis/summarymesh_hexgon_96_101_001 |
| 是否创建表 | 是 | 当数据表不存在时,是否主动创建一个新表,true是,false否 |
| MapGIS格式 | 是 | 是否创建并初始化为MapGIS格式,true是,false否 |
| 用户名 | 否 | 访问数据表所用的用户名,如sample |
| 密码 | 否 | 访问数据表所在数据库的密码,如sa |
| 批量大小 | 否 | 系统采用缓存,批量提交方式提升大数据量下的性能,默认是10000 |
| 连接池大小 | 否 | 系统采用数据库连接池来提升大数据量下写入的性能,默认为1 |
# 流计算服务管理
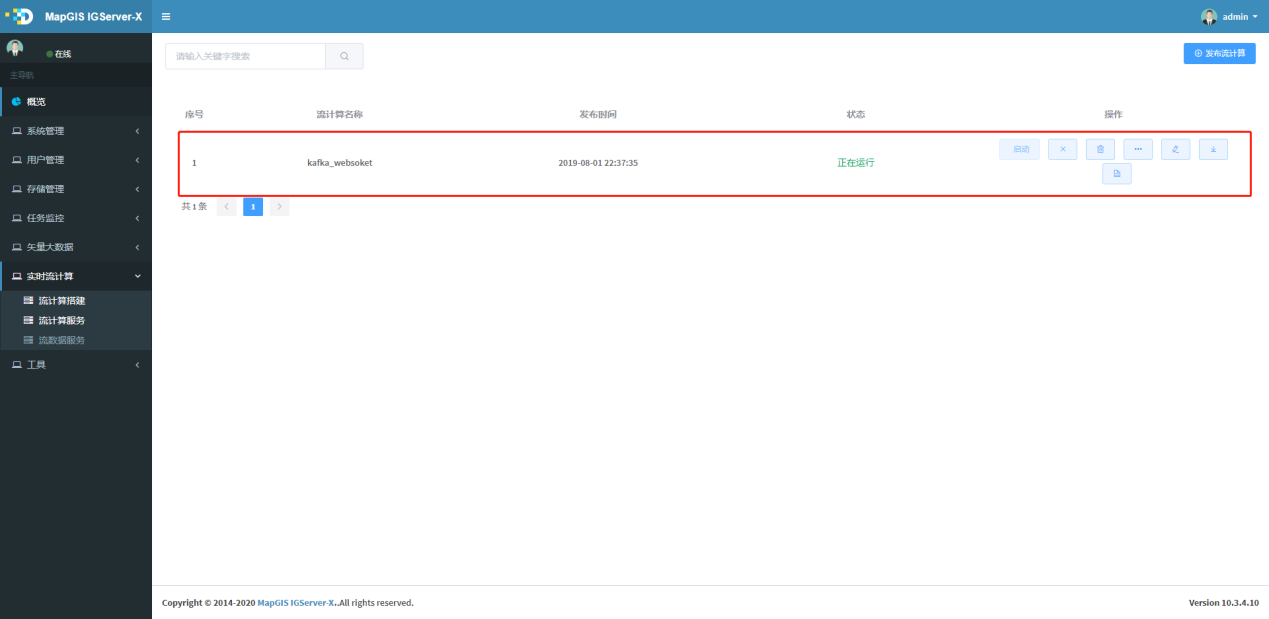
# 查看流计算服务
1. 进入实时流计算菜单中流服务计算界面,在该页面默认会显示所有发布的服务,可通过输入关键词,检索到相关的服务列表,如下图所示:
# 发布流计算服务
1. 点击流计算服务界面右上角的 按钮,弹出发布设置界面,如图所示,:
按钮,弹出发布设置界面,如图所示,:

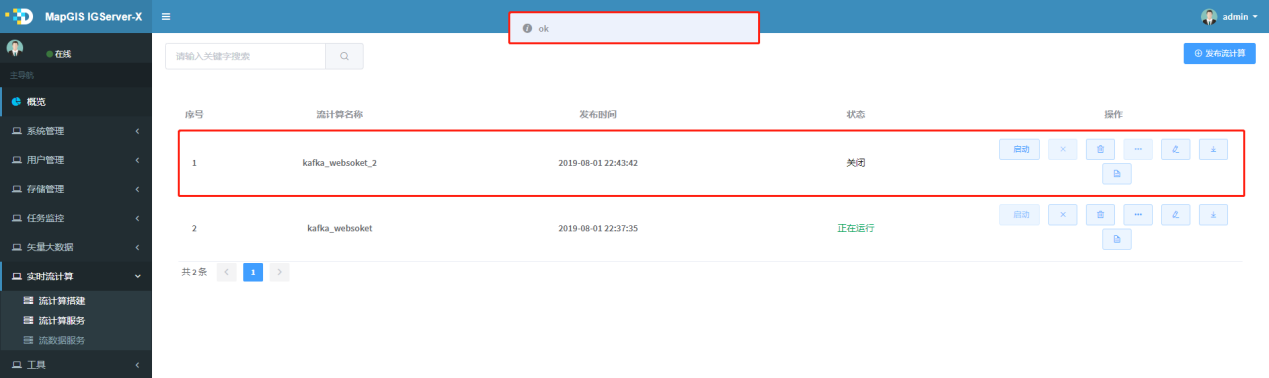
2. 选择构建好的json服务定义文件,点击确认,会发布该服务,发布成功会提示ok,发布成功的服务会进入流计算服务列表,如图所示,:
# 删除流计算服务
1. 点击待删除服务行右边的 按钮,弹出删除确认界面,点击"确定",即可删除相应的服务,如图所示,:
按钮,弹出删除确认界面,点击"确定",即可删除相应的服务,如图所示,:
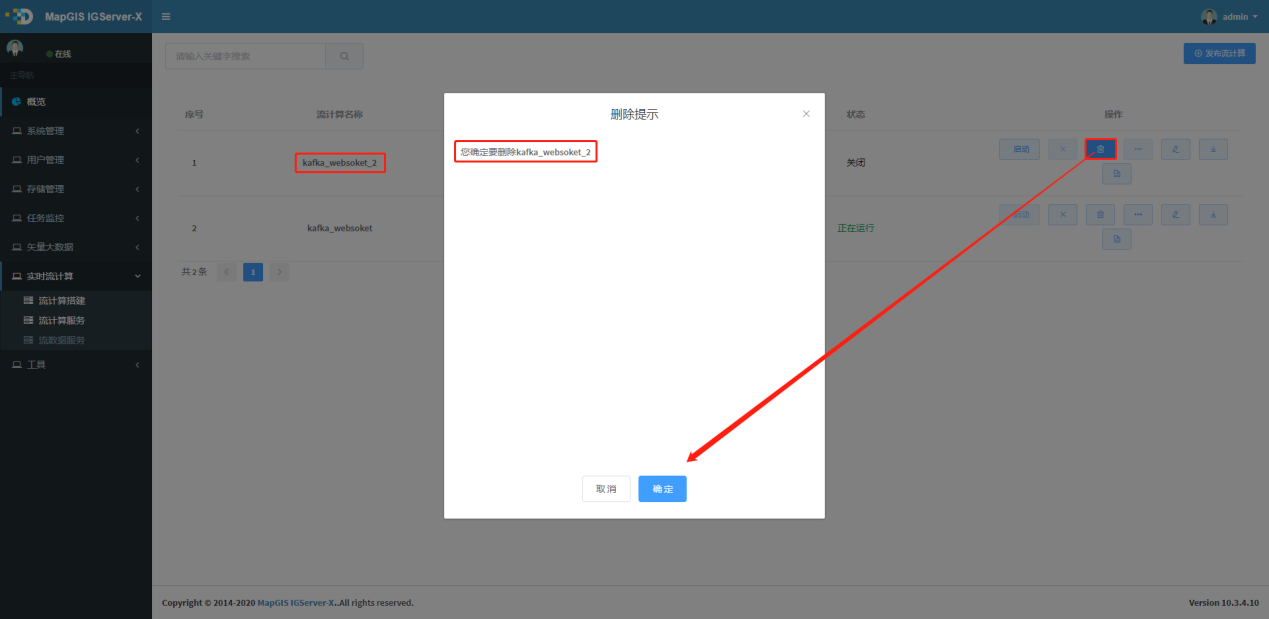
# 启动流计算服务
1. 待启动服务行右边的 按钮,弹出启动操作状态提示,如图所示,:
按钮,弹出启动操作状态提示,如图所示,:
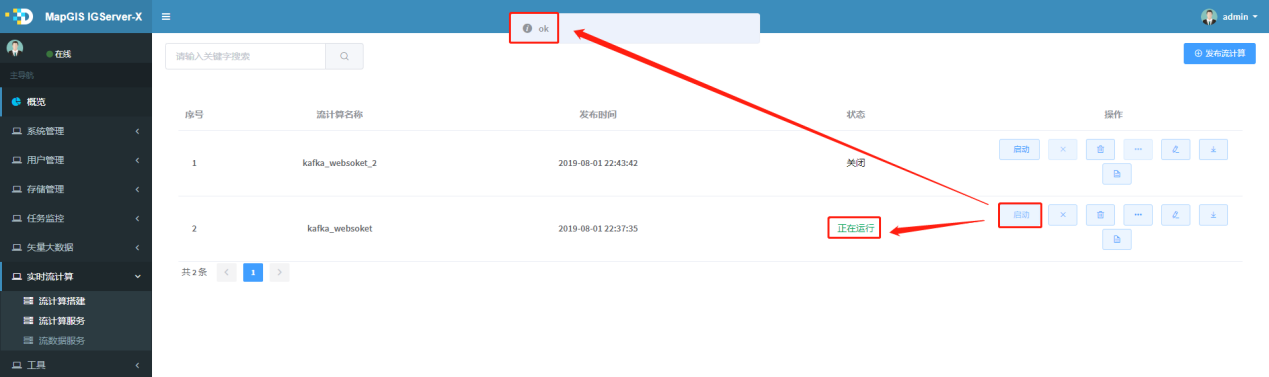
提示:
启动前,请保证依赖的其他服务是启动状态,比如流程依赖的kafka、socket程序或es、ws服务,请先开启kafka、socket、es等程序
# 关闭流计算服务
1. 点击待关闭服务行右边的 按钮,弹出关闭操作状态提示,如图所示,:
按钮,弹出关闭操作状态提示,如图所示,:
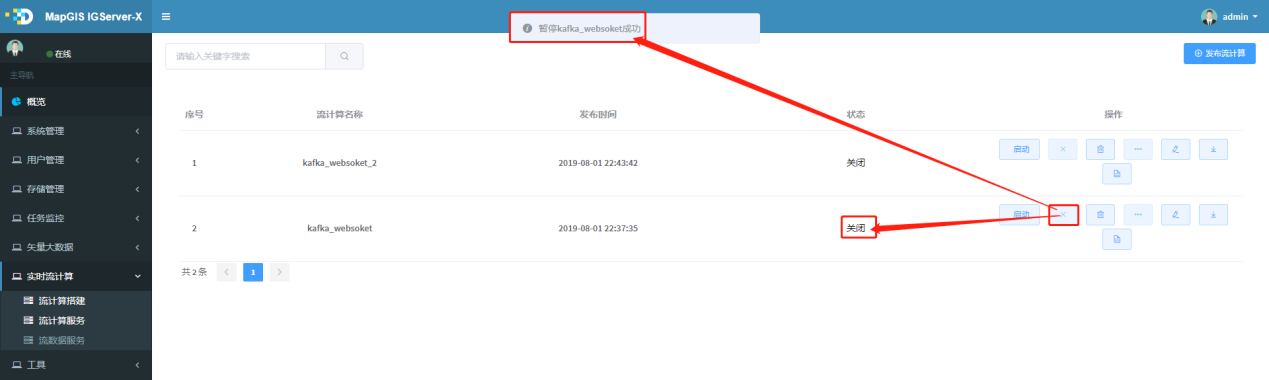
# 监控流计算服务
1. 点击待查看服务行右边的 按钮,弹出任务状态详情界面,如图所示:
按钮,弹出任务状态详情界面,如图所示:
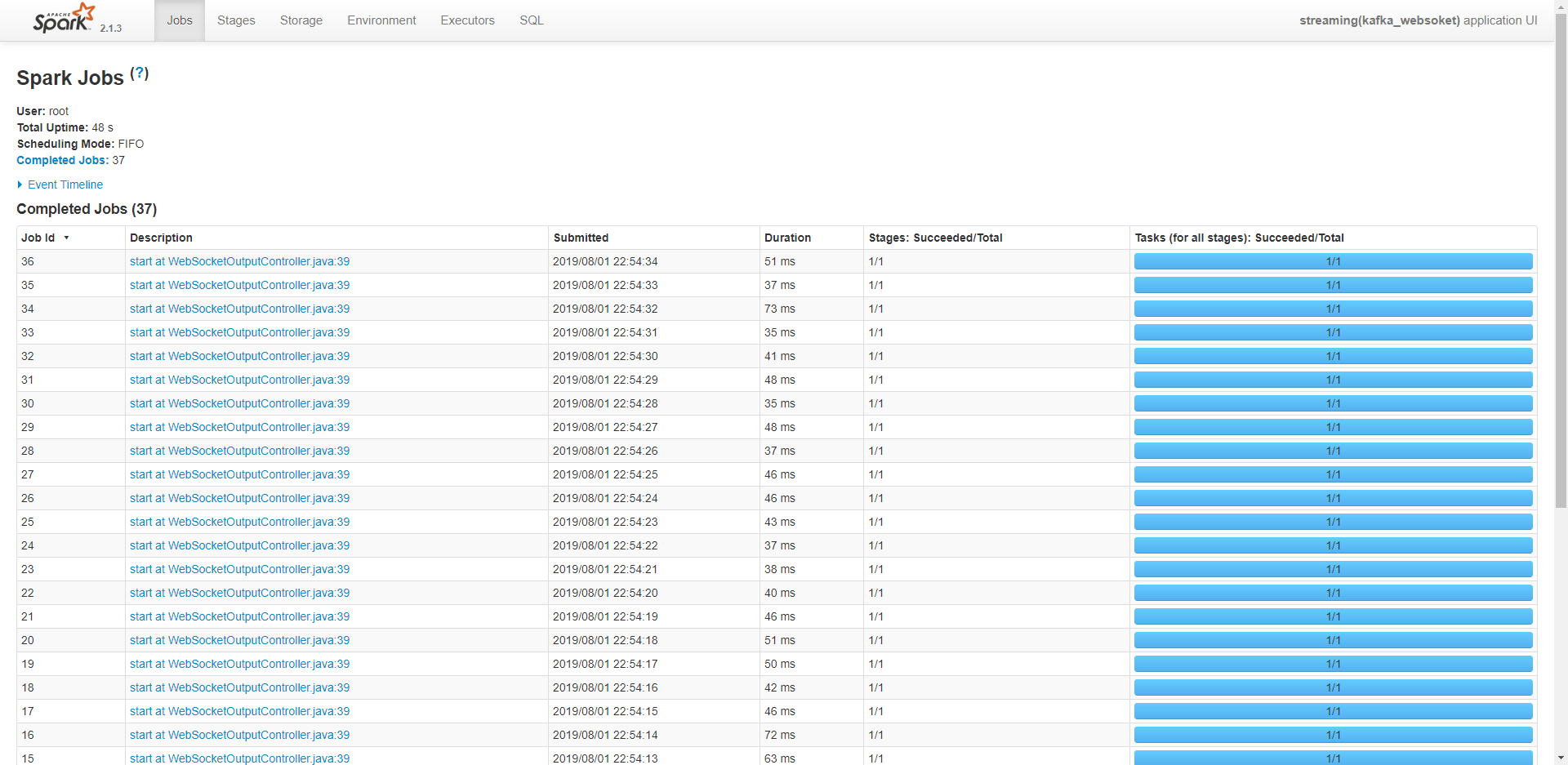
2. 点击其中的连接,可查看计算任务的详细信息,如可执行任务数及执行情况,及执行节点等。
# 流数据服务管理
# 查看流数据服务
1. 进入实时流计算菜单中流数据服务页面,在该页面默认会显示所有发布的服务,可通过输入关键词,检索到相关的服务列表,如下图所示:
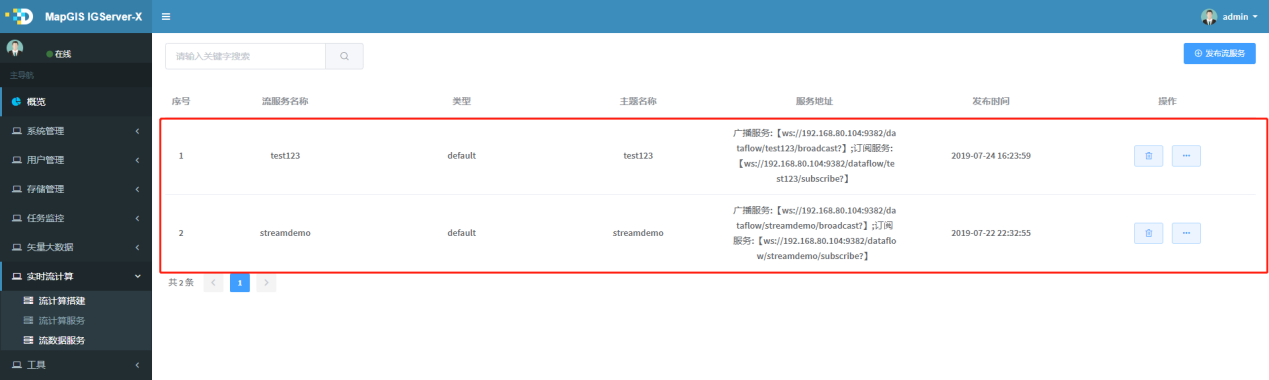
# 发布流数据服务
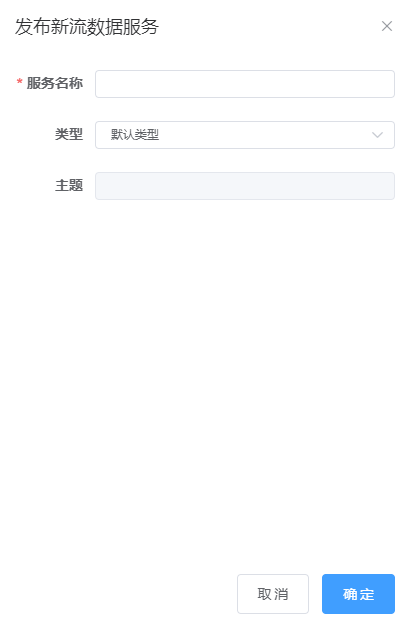
1. 点击流数据服务右上角的 菜单,弹出发布设置界面,配置对应参数,点击确认,会发布该服务,流数据服务支持默认的WebSocket和kafka两种数据来源的服务,如图所示;
菜单,弹出发布设置界面,配置对应参数,点击确认,会发布该服务,流数据服务支持默认的WebSocket和kafka两种数据来源的服务,如图所示;
2. 成功后,可在流数据服务列表看到发布成功的流数据服务;
# 删除流数据服务
1. 点击待删除行右边的 按钮,弹出删除确认界面,点击"确定",即可删除相应的服务;
按钮,弹出删除确认界面,点击"确定",即可删除相应的服务;
# 监控流数据服务
1. 点击待查看服务行右边的 按钮,弹出流数据状态详情界面,如图所示,:
按钮,弹出流数据状态详情界面,如图所示,:

2. 查看流数据服务详情有两种模式,数据模式和地图模式,可以点击下图中的下拉框选择,如图所示,:
