# 文本大数据
# 功能服务
提示:
界面将数据上载到系统中,请在对应的实时存储和HBase存储中创建好时空库或者内容库。
# 创建文本索引
#  功能说明
功能说明
对输入的HDFS上的doc、pdf、xls等文档中的文本进行提取,并在ES中生成全文内容检索字段__inner__content,从而提供全文检索查询能力,且DataStore中对此字段的查询服务对结果中的关键词会增加高亮标签<em></em>;针对此输入也可是HBase中的文本内容数据表,若为此,需要给定关联ID参数,详见参数说明。
#  操作说明
操作说明
1. 进入"文本大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击创建文本索引任务,进入参数配置页面,参数见下说明,如下图所示:
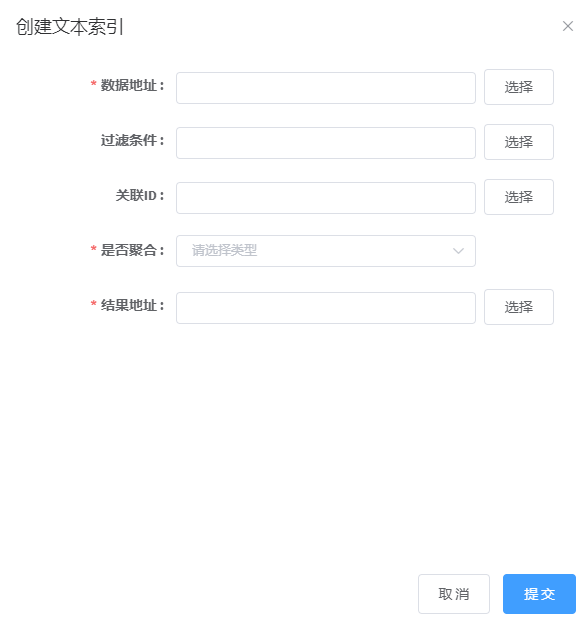
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
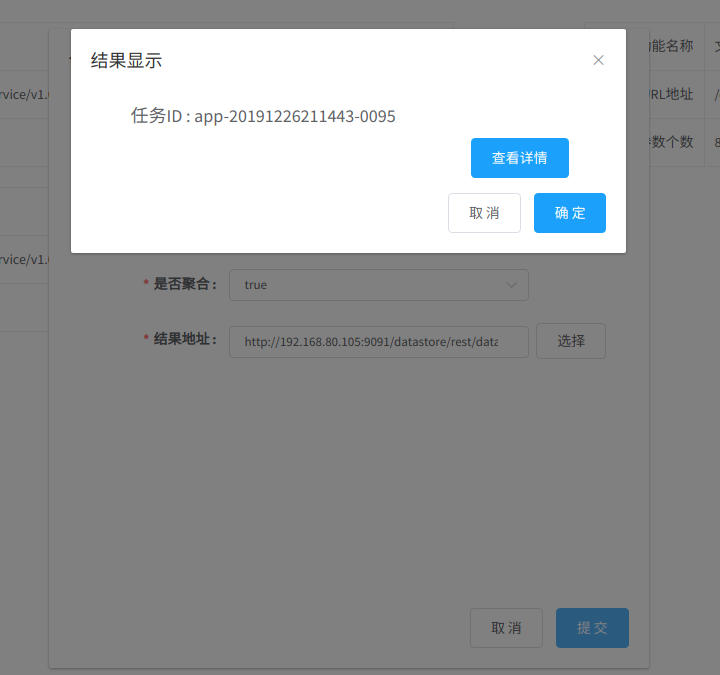
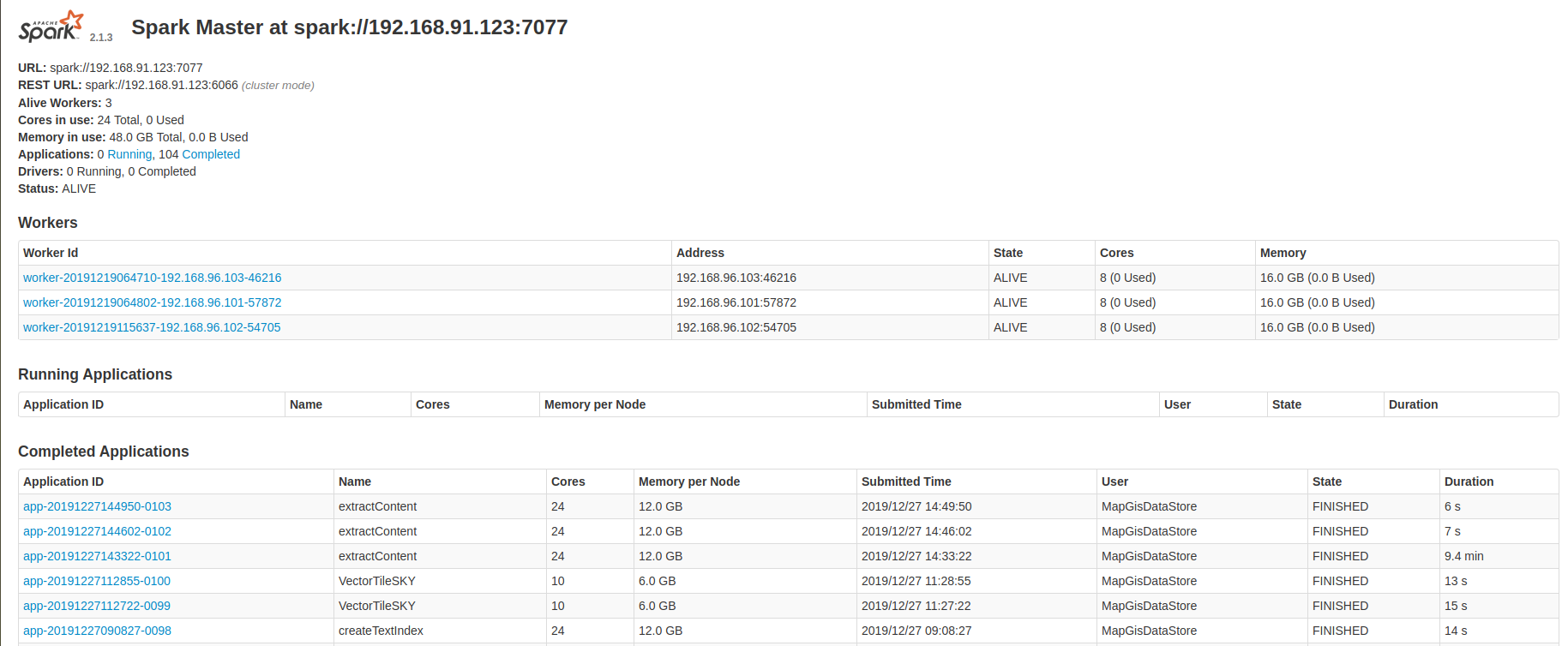
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入IGServer-X中任务监控列表,也可以进入Spark监控页面查看任务执行情况,此任务名createTextIndex关键词。
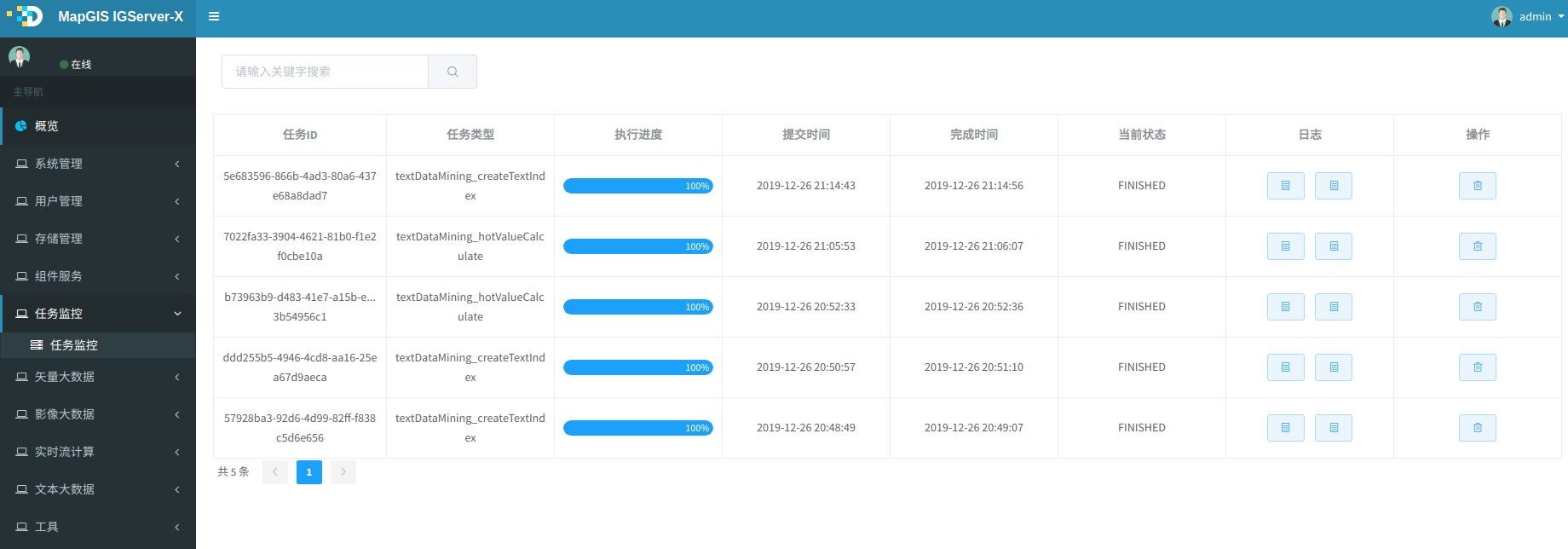
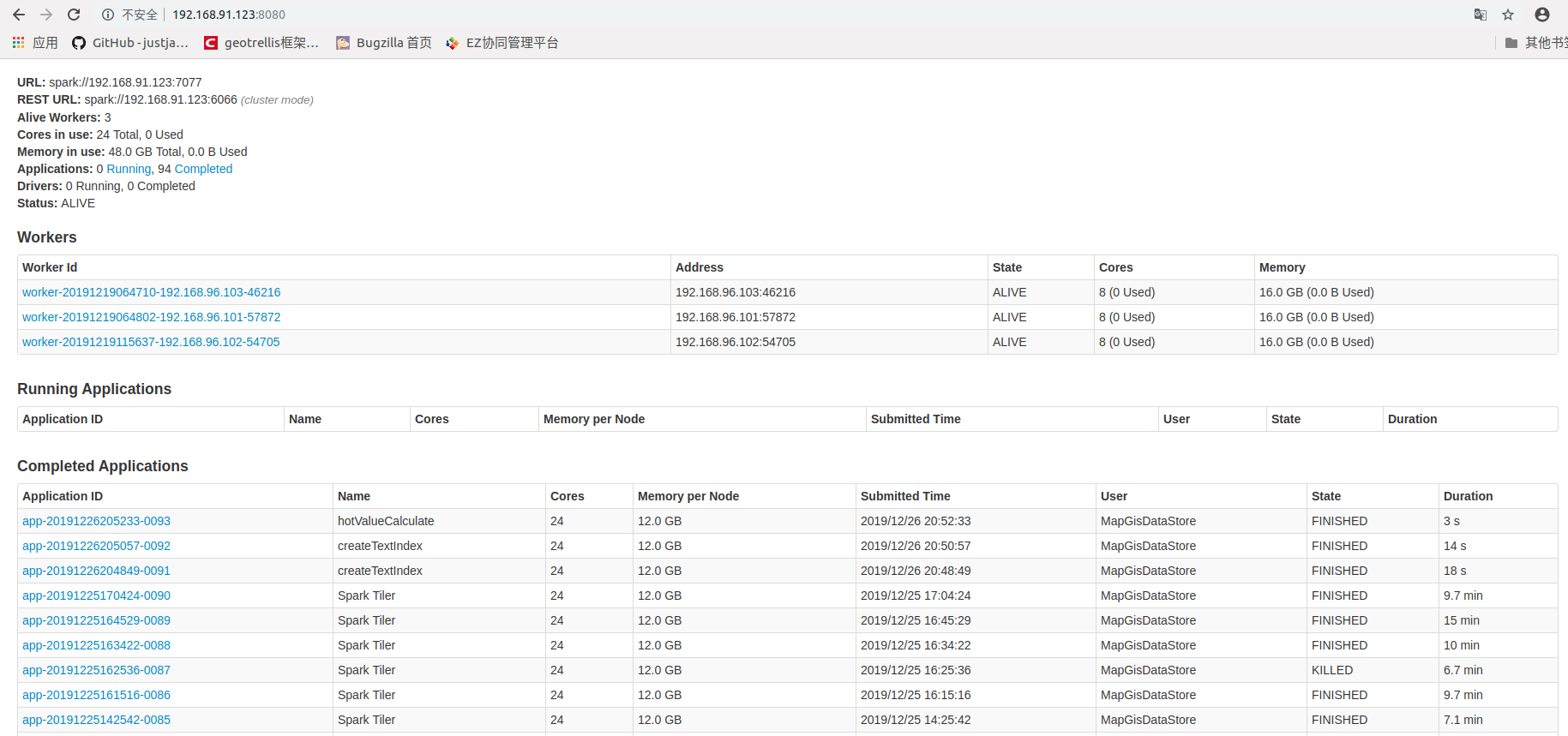
5. 待正常执行完后,则可在DataStore目录中看到结果,会增加或更新__inner__content字段的内容。
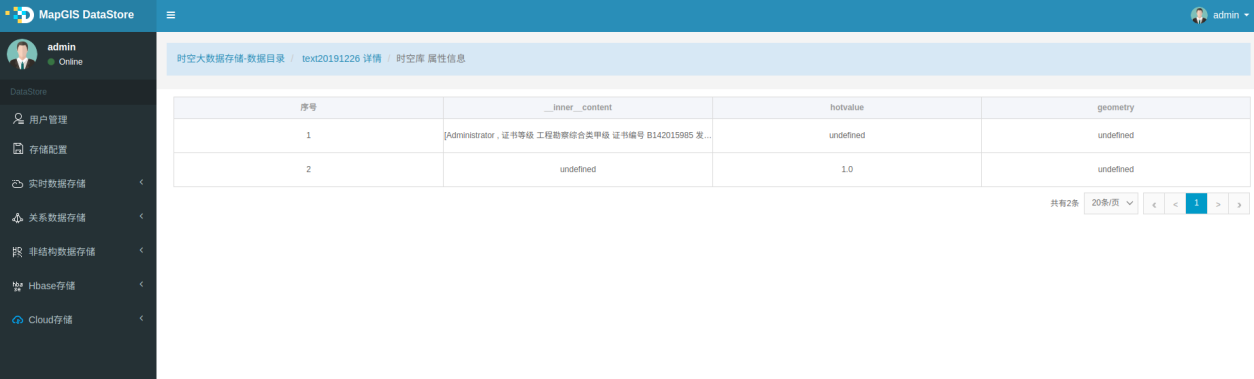
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 原始数据 | 原始HDFS数据或HBase文本内容数据地址,即支持HDFS、HBase中的路径 | http://192.168.80.108:9091/datastore/rest/dataset/ hdfs/service/archives/测试报告 | 必填 | |
| 过滤条件 | 过滤条件,文件相对路径模糊匹配,多个用逗号分割 | /*.docx,/附图/*.mpj,/附图/*.jpg | 可选 | |
| 关联ID | 关联的ID,若不使用外部ID,且给的数据是HBase的文本内容数据,该参数请给HDFS数据的路径,以便系统内部使用MD5计算默认关联ID | 1111 | 可选 | |
| 是否聚合 | 是否聚合为一条记录,用于一条元数据对应多个文件的场景 | true | 可选 | |
| 结果地址 | 索引库的URL地址 | http://192.168.80.108:9091/datastore/rest/dataset/ hbase/service/test? | 必填 |
# 文档内容提取
# 功能说明
该功能对输入的HDFS上的doc、pdf、xls等文档内容进行提取转换,形成统一的html格式的文本内容,同时提取出内嵌在文档中的图片、视频、音频等多媒体内容,保存到HBase数据表中,供后续查询、分析使用;在内容提取的同时,可附加选择在ES中创建文本索引;
# 操作说明
1. 进入"文本大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击内容提取任务,进入参数配置页面,参数见下说明,如下图所示:

3. 输入参数,点击提交按钮,若正在提交,则显示如下图.
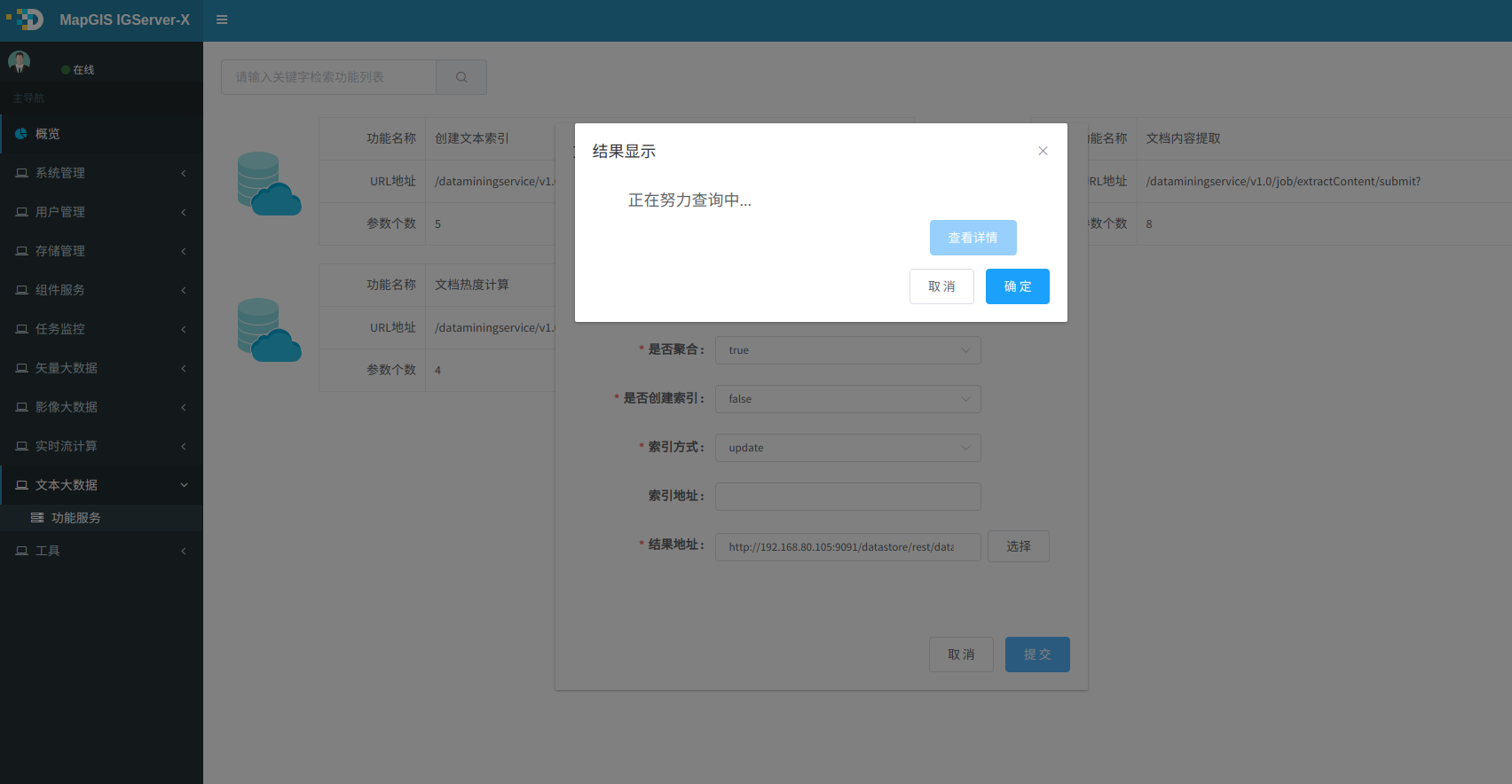
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入自带的任务列表或者Spark监控页面查看任务执行情况。
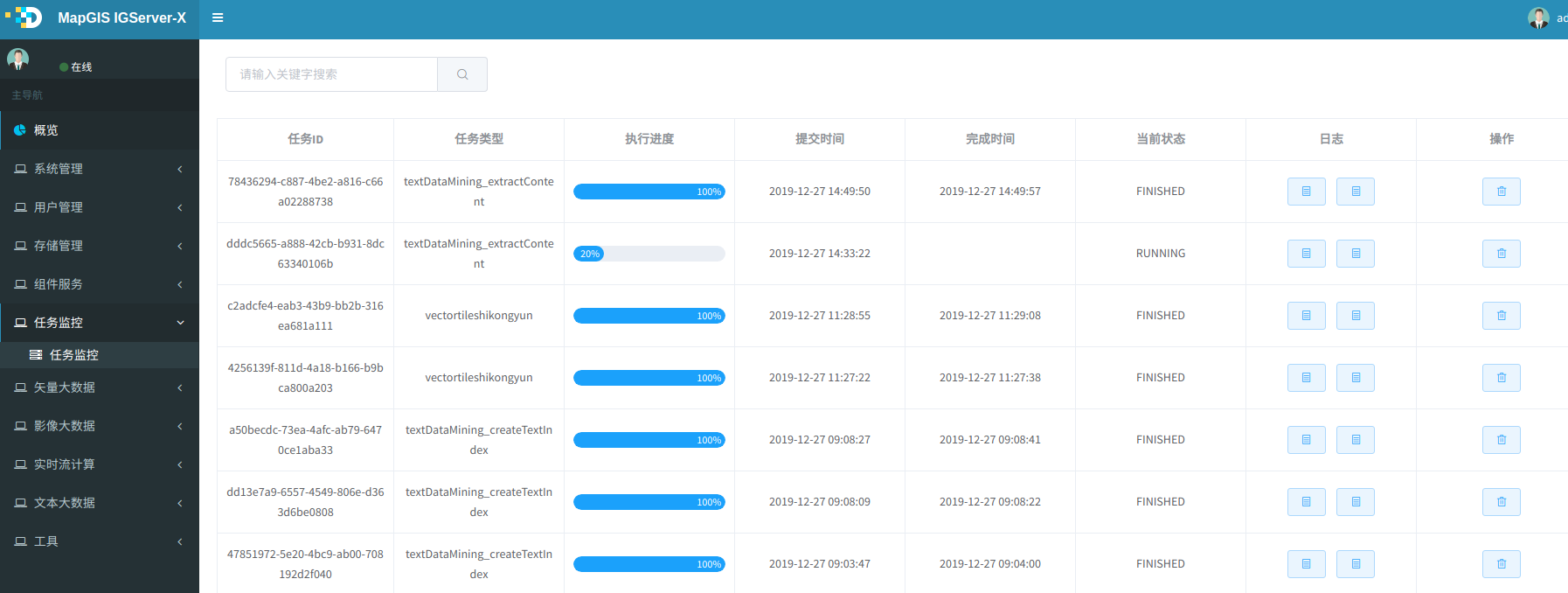
5. 待正常执行完后,则可在DataStore对应的存储目录中看到有结果数据。
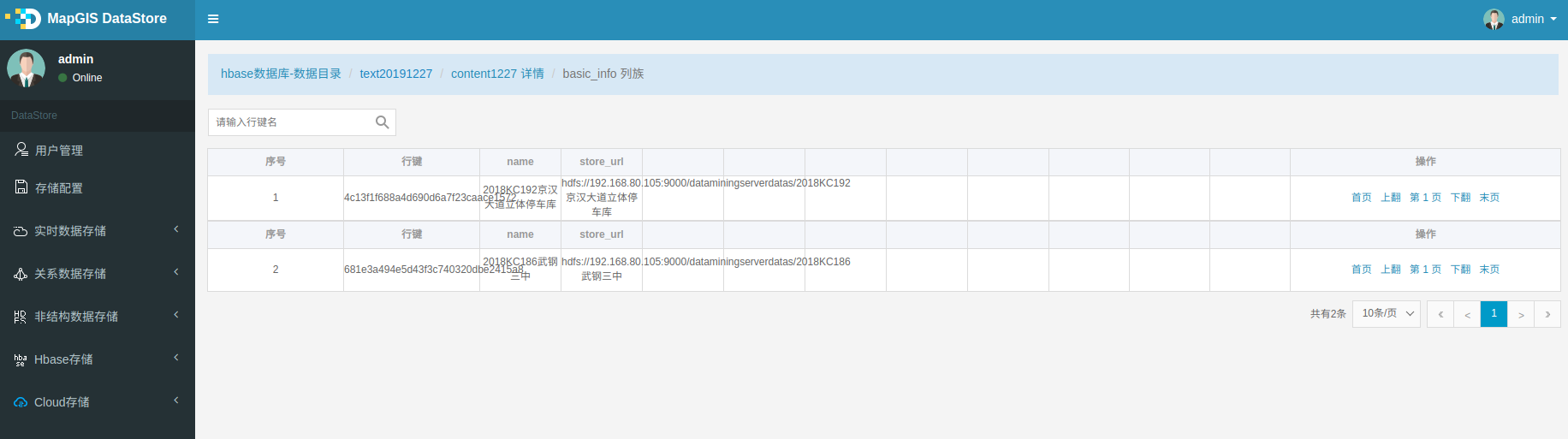
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 数据路径 | 原始数据路径,支持HDFS | http://192.168.80.108:9091/datastore/rest/dataset/ hdfs/service/archives/测试报告 | 必填 | |
| 过滤条件 | 路径过滤条件,文件相对路径模糊匹配,多个用逗号分割 | /*.docx,/附图/*.mpj,/附图/*.jpg | 可选 | |
| 关联ID | 关联的ID,若不使用外部ID,即默认使用hdfs上文件夹的路径做md5计算后的值作为关联ID | 1111 | 可选 | |
| 是否聚合 | 是否聚合为一条记录,用于一条元数据对应多个报告文件的场景 | true | 可选 | |
| 是否索引 | 是否同时创建索引 | false | 可选 | |
| 索引方式 | 支持update、rebuild两种方式,update只创建满足过滤条件的索引,rebuild为创建全量索引 | update | 可选 | |
| 索引库地址 | 索引库的URL地址 | http://192.168.80.108:9091/datastore/rest/dataset/ es/service/test/文本库? | 可选 | |
| 结果地址 | 结果保存内容库的URL地址 | http://192.168.80.108:9091/datastore/rest/dataset/ hbase/service/test? | 必填 |
# 文档热度计算
# 功能说明
该功能通过对文档报告的搜索记录、浏览记录、访问记录、收藏记录等用户行为,结合报告文本内容,综合对文档报告的访问热度进行计算,应用系统可根据文档报告的热度进行优先排序、推荐等。
# 操作说明
1. 进入"文本大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击文档热度计算任务,进入参数配置页面,参数见下说明,如下图所示:
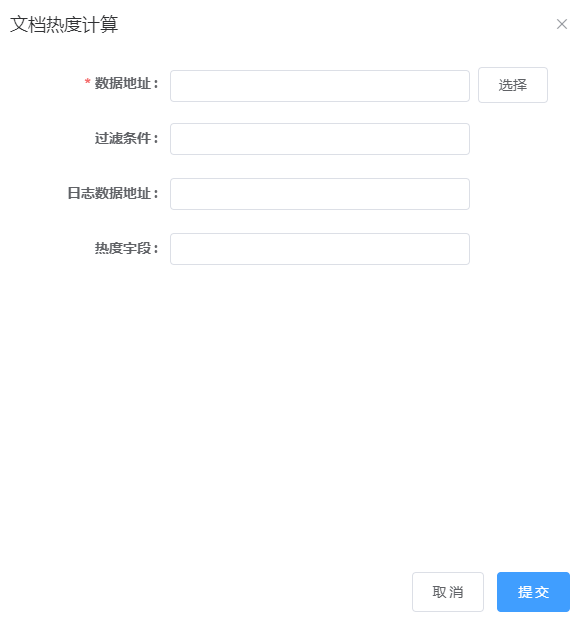
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
5. 待正常执行完后,则可在DataStore目录中看到结果
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 索引库地址 | 索引库中文档数据地址 | http://192.168.80.108:9091/datastore/rest/dataset/ es/service/test/文本库? | 必填 | |
| 过滤条件 | 过滤条件,对要计算的数据进行过滤 | ID>5 | 可选 | |
| 日志数据地址 | 历史搜索词数据地址,支持es和HDFS两种存储,默认为ES索引库中文档关搜索关键词记录表 | Hdfs日志文件为txt,格式如下(一行一个搜索关键词):  | 可选 | |
| 热度字段 | 热度字段名称,计算结果保存字段,默认为__inner__hot | __inner__hot | 可选 |
# 文档报告内容提取
# 功能说明
该功能能够按段落解析doc文档的内容,并将内容存储到elasticsearch中。
# 操作说明
1. 进入"文本大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击文档报告内容提取任务,进入参数配置页面,参数见下说明,如下图所示:
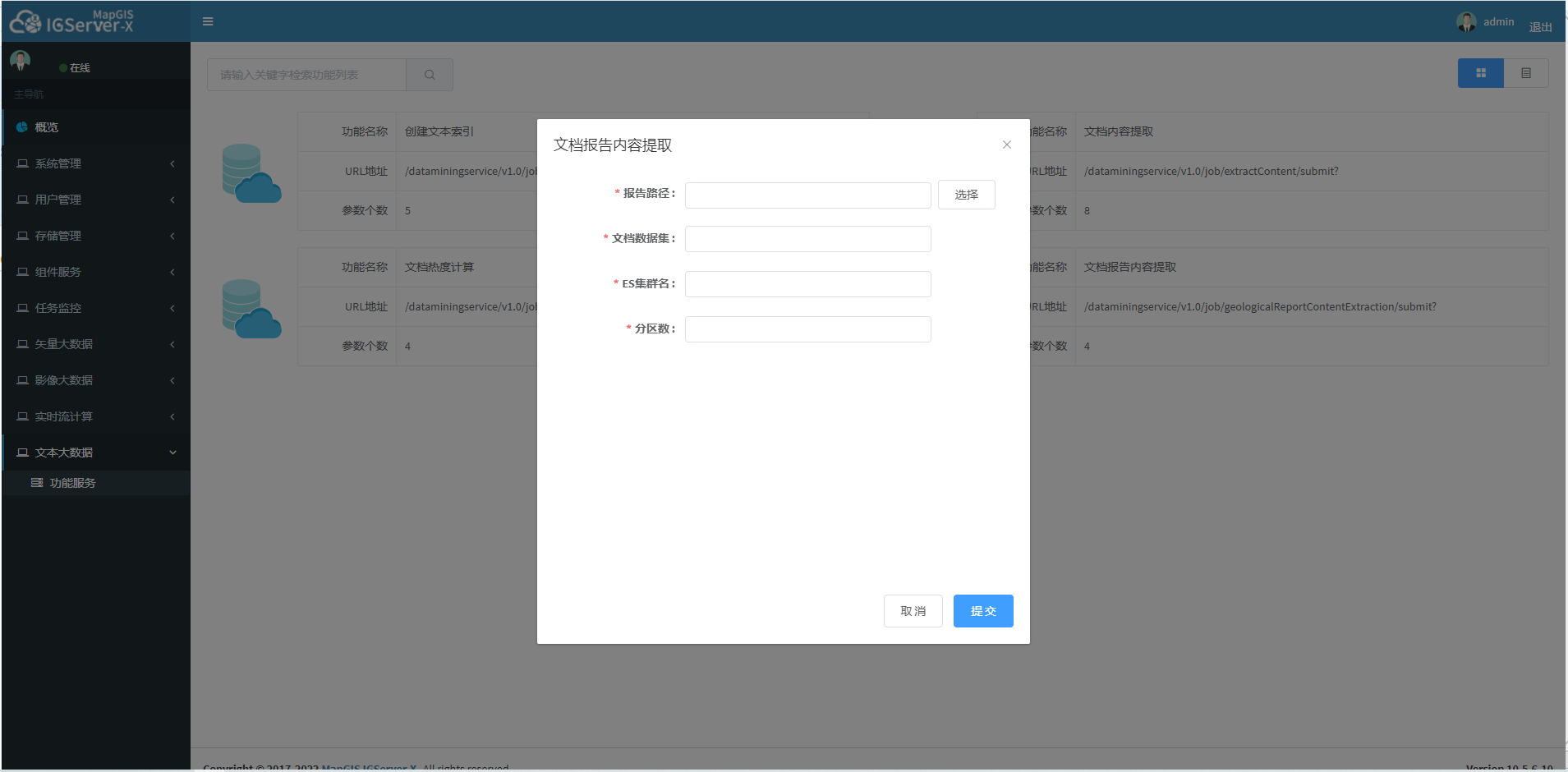
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
5. 待正常执行完后,则可在DataStore目录中看到结果
参数说明
| 参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 报告路径 | 报告存储在hdfs上的路径 | hdfs://192.168.199.50:9000/doc/工勘报告 | 是 | |
| 文档数据集 | 文档数据集的地址url | es://192.168.199.50:9300/testdb_mdo_1652085892030/def | 是 | |
| ES集群名 | es集群的名称 | escluster | 是 | |
| 分区数 | 任务并行度 | 5 | 是 |