# 矢量大数据
基于Spark的矢量大数据计算是将GIS与Spark计算框架深度融合,提供海量矢量数据的分布式计算服务能力。通过MapGIS SDE和MapGIS DataStore存储海量矢量数据,进而通过分布式存储的基础上快速构建分布式要素数据集FeatureRDD,其能够将MapGIS基础算法与Spark计算框架进行深度融合,所覆盖的基础算法包括几何计算、空间判断、空间分析等,通过Spark框架实现分布式空间运算,并能将计算结果通过FeatureRDD快速写回到MapGIS DataStore和MapGIS SDE。矢量大数据计算服务能够支持亿万级矢量数据的分布式空间计算,相对于传统计算模式性能有明显的提升,满足海量矢量数据快速计算的应用需求。
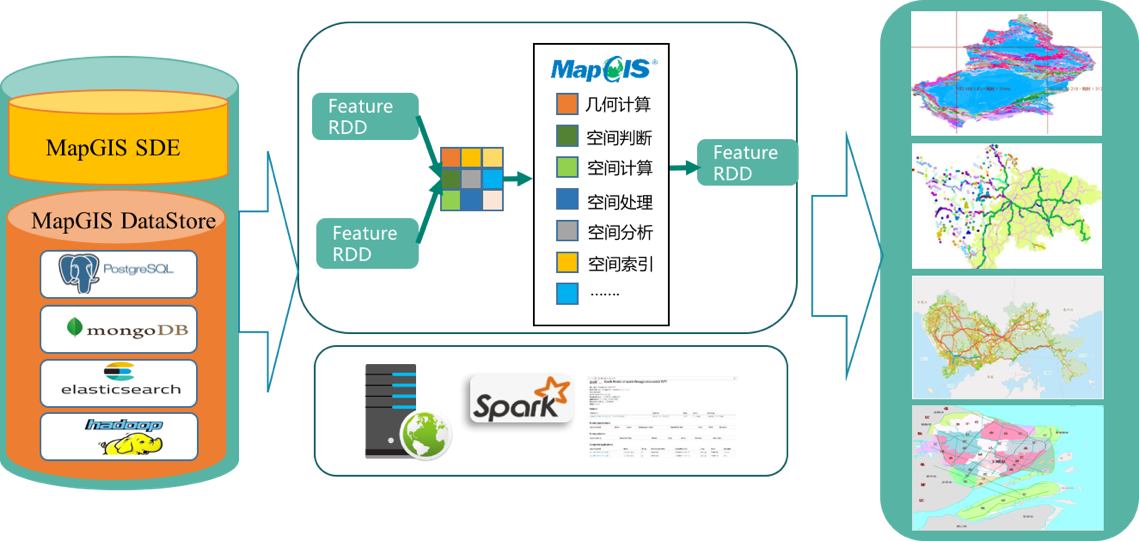
# 数据管理服务
# 拷贝数据任务
#  功能说明
功能说明
该功能主要用于DataStore中存储组件间复制数据,或者从外部本地/HDFS共享的文本型矢量数据(GeoJSON、Json、CSV、Text等)转换复制到DataStore存储。
拷贝数据任务主要用于数据迁移,可以在postgresql、hdfs(后续可能会支持es、hbase)间拷贝数据,拷贝过程中支持对数据进行过滤。
#  操作说明
操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击拷贝数据任务,进入参数配置页面,参数见下说明,如下图所示:
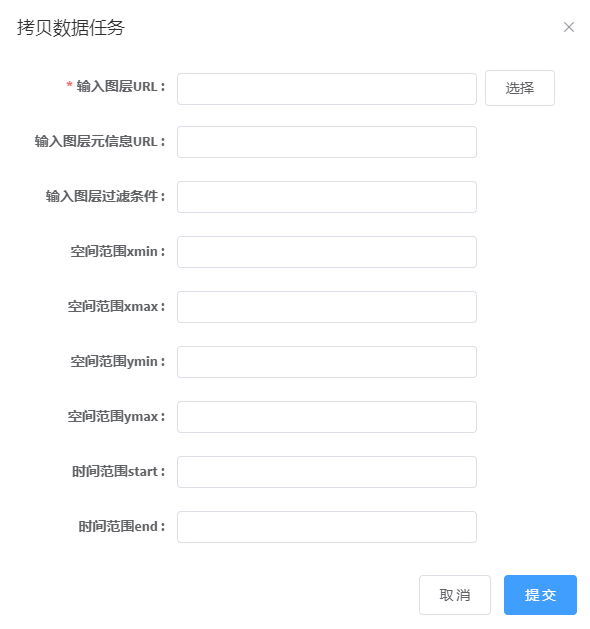
3. 输入参数,点击提交按钮,若正在提交,则显示如下图:

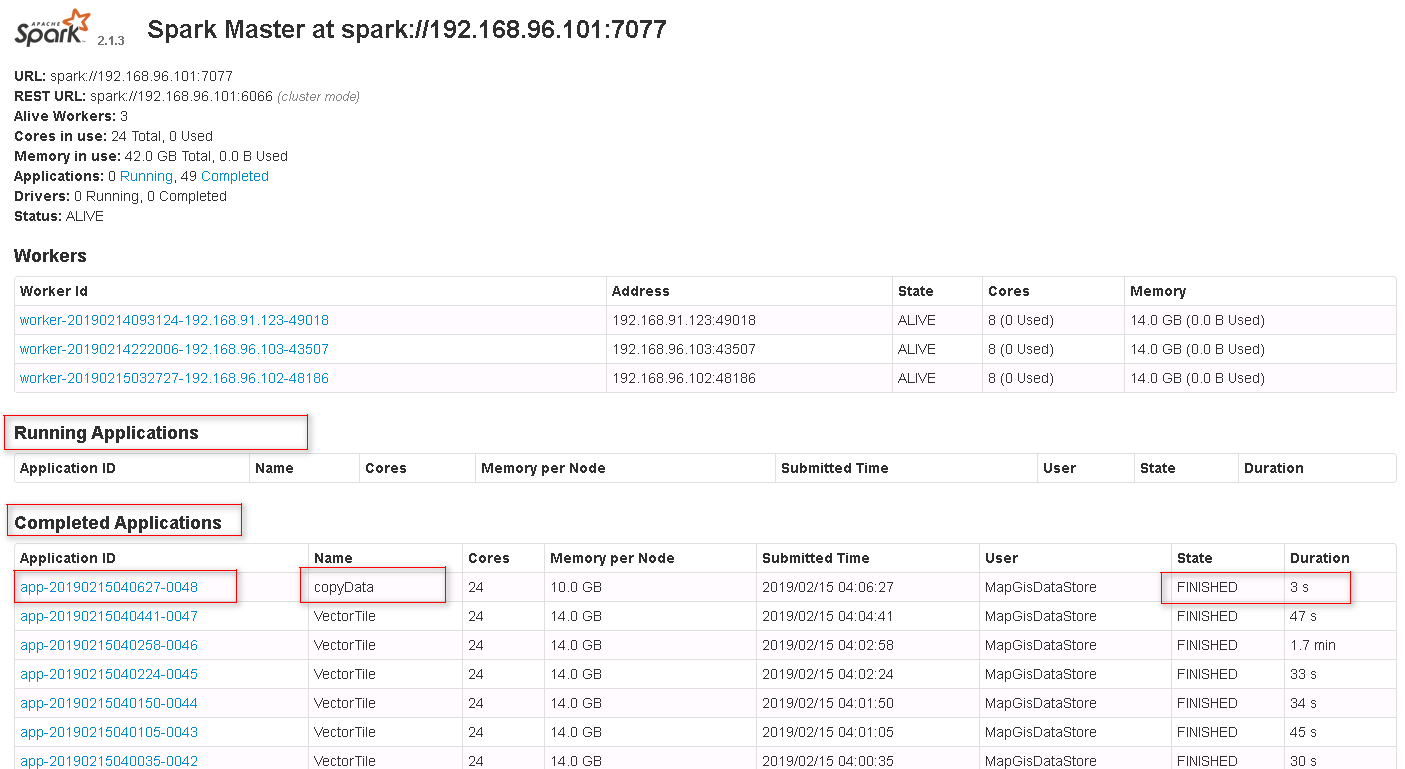
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。

5. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。


参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/ dataset/pg/service/show/show/JBNT_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 结果图层URL | 拷贝目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/ postgis/summarymesh_hexgon_96_101_001 | 是 |
# 创建索引
# 功能说明
该功能主要用于对静态大矢量数据基于预先在HDFS存储中建立格网一层空间索引,减少其他分析功能直接从数据库读取原始数据的过程,从而加快分析计算功能。
创建索引服务用于对矢量空间数据建立空间二级索引(第一级:根据划分好的矩形网格,将空间数据分文件存储;第二级:每个网格中的空间数据建立Rtree索引),并将索引数据存放在HDFS上
# 操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
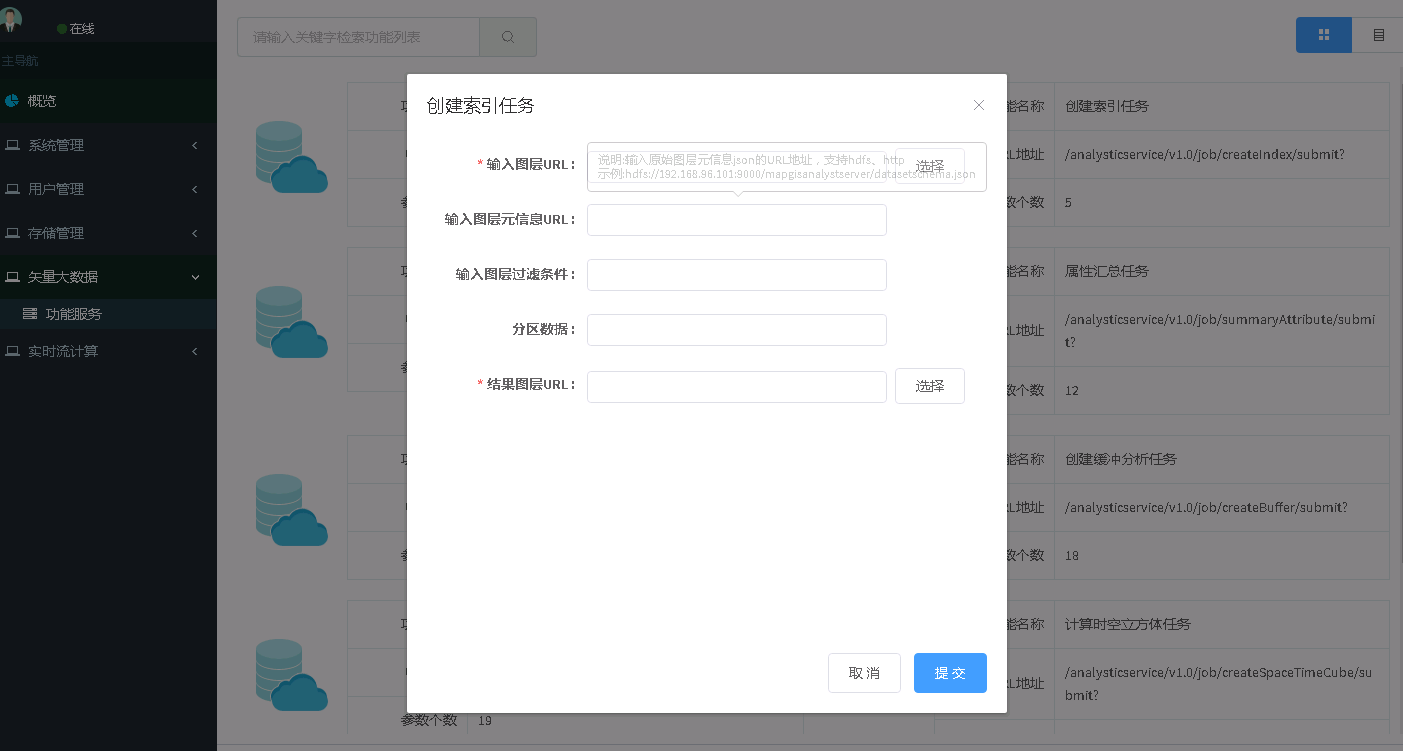
2. 点击创建索引任务,进入参数配置页面,参数见下说明,如下图所示:
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
5. 待正常执行完后,则可在DataStore中非结构化存储目录中看到结果,如下图所示。
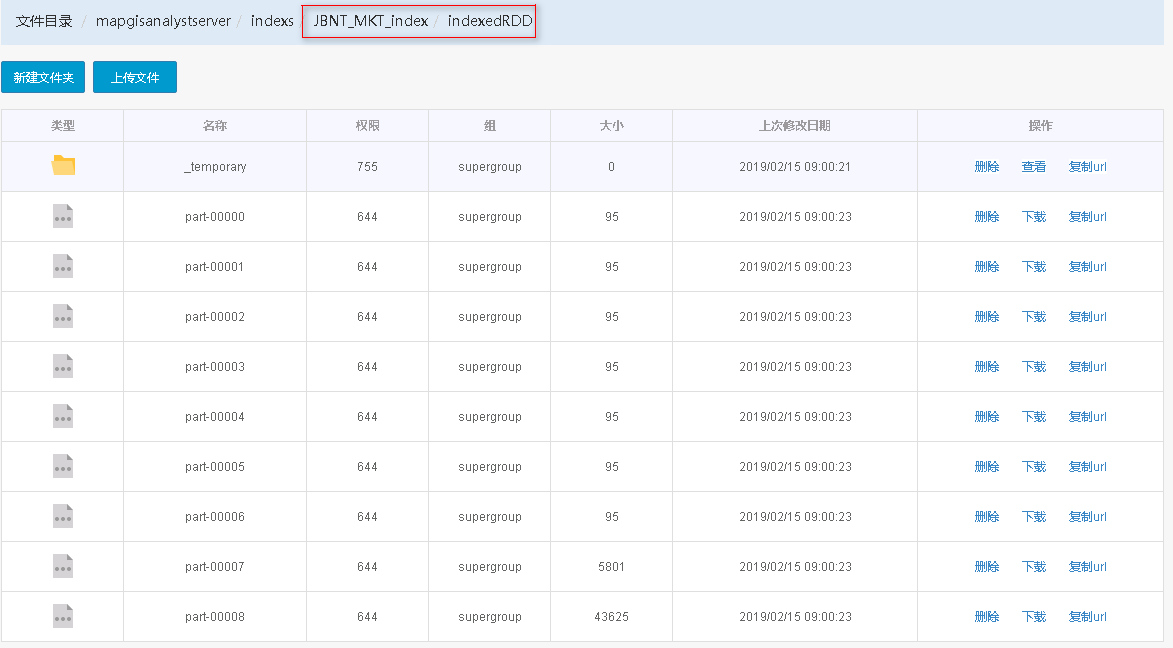
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/JBNT_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 分区数 | Spark并行任务数 | 10 | 是 | |
| 结果图层URL | 索引存放目录 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 | 是 | Hdfs空目录 |
# 计算字段
# 功能说明
对存储在DataStore中矢量数据,使用该工具来创建和填充新属性字段或编辑现有字段,从而生成一份具有新属性的矢量数据。
# 操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击计算字段任务,进入参数配置页面,参数见下说明,如下图所示:
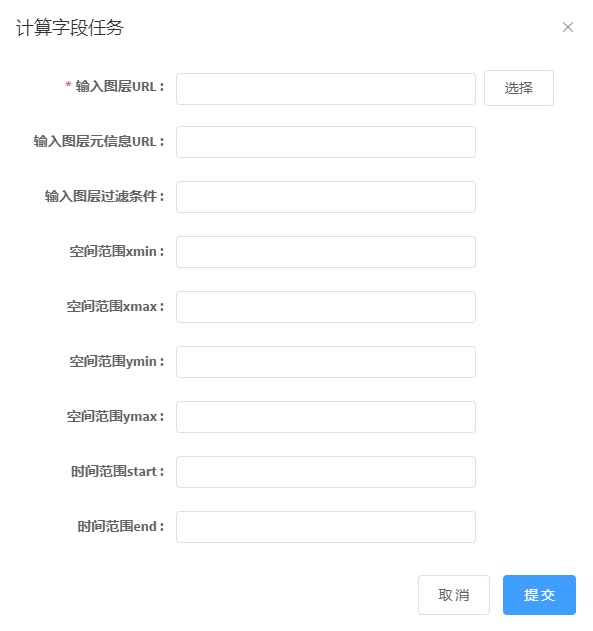
3. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
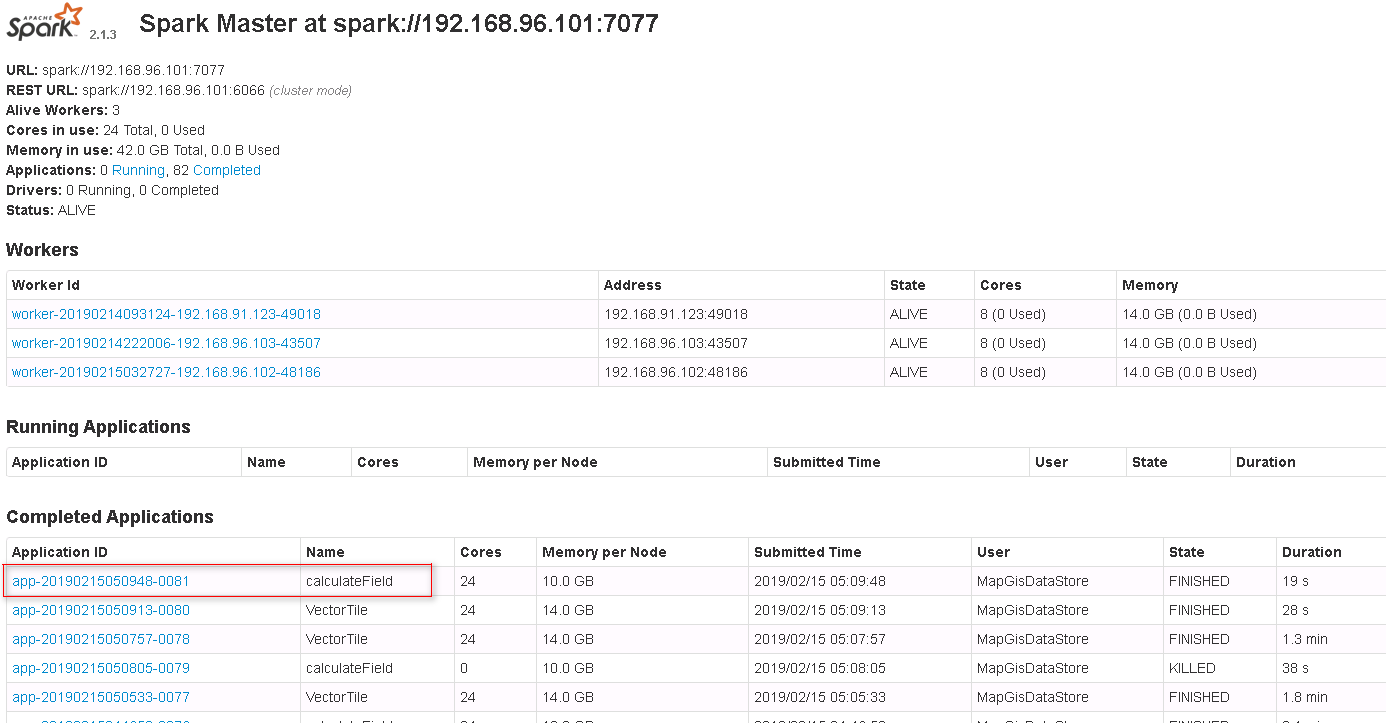
4. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。
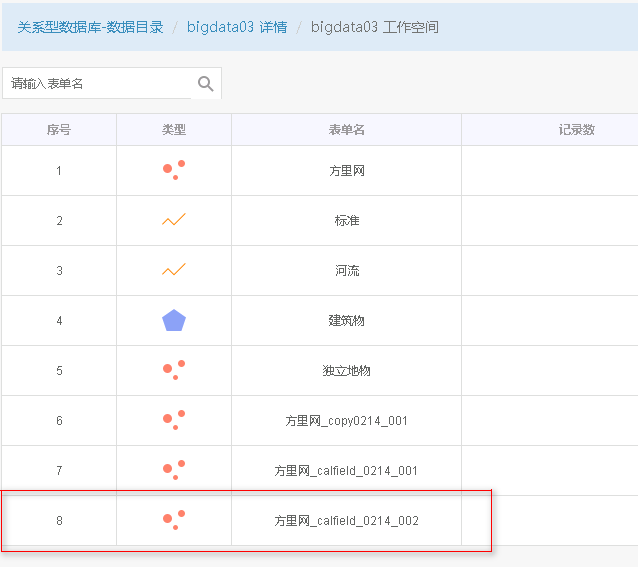
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/JBNT_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 输入图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 新字段名 | 新字段名称 | newFld | 是 | |
| 新字段类型 | 新字段的类型 | DOUBLE | 是 | |
| 计算表达式 : | 新字段取值的计算表达式。 | fld0*(fld1+20)-fld2 | 是 | |
| 结果图层URL | 目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 | 是 | |
| 结果图层数据库用户 | 结果存储数据库的用户名 | 否 | ||
| 结果图层数据库密码 | 结果存储数据库的用户密码 | 否 |
# 矢量瓦片裁剪
# 功能说明
该功能主要用于并行快速创建矢量数据金字塔结构,即矢量瓦片,生成的瓦片数据保存在mongodb缓存数据库中,WebClient前端能直接对接瓦片服务,从而浏览地图。
矢量瓦片裁剪服务基于spark分布式计算框架,提供批量生成矢量瓦片的能力;输入为矢量图层(支持多图层),输出为对应的pbf文件。
# 操作说明
1. 准备好需要裁剪的原始数据,并将原始数据存储到MapGisDataStore的矢量大数据中。该过程可以直接通过mapgis桌面注册postgresql数据源完成。
2. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
3. 点击矢量瓦片裁剪任务,进入参数配置页面,参数见下说明,如下图所示:
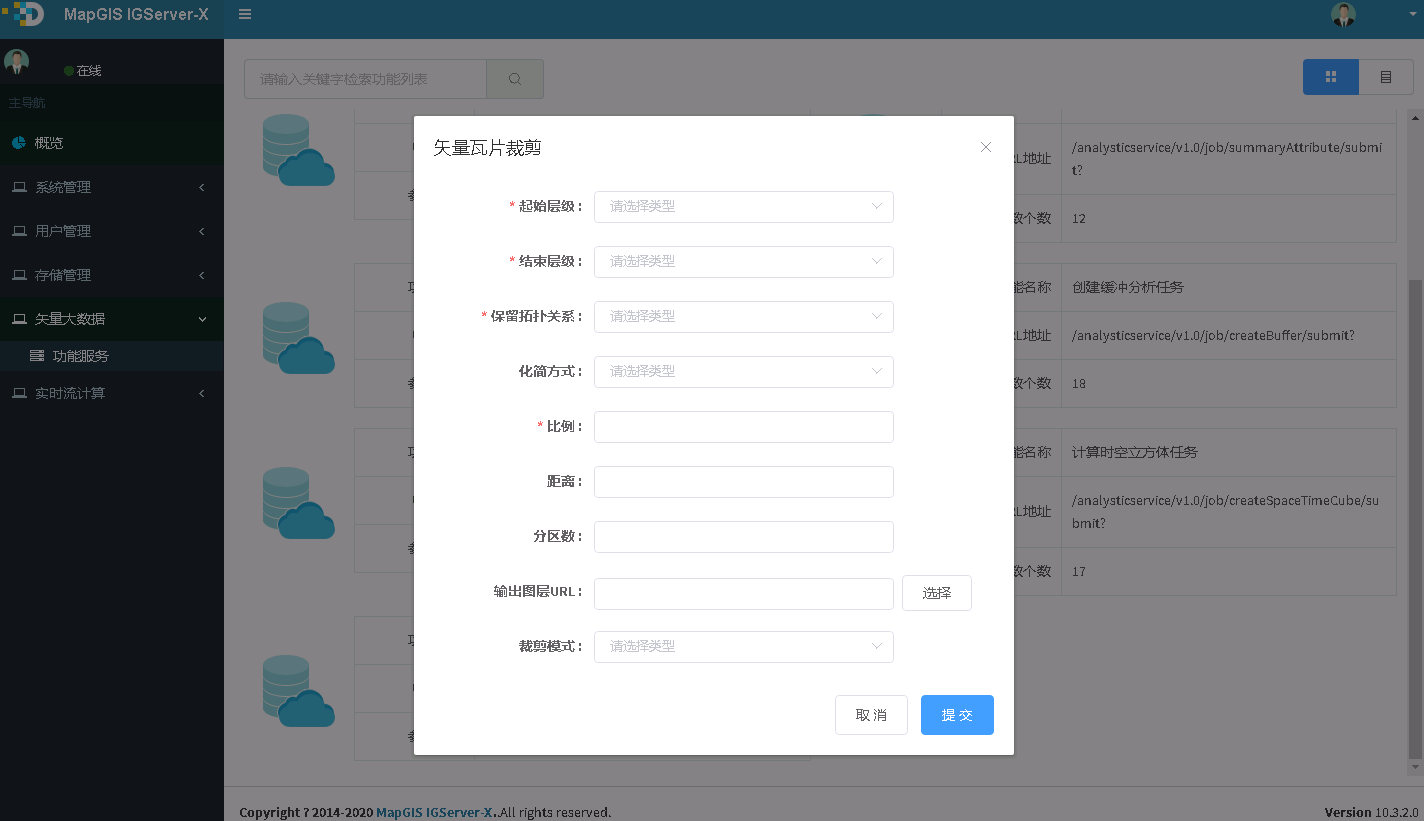
4. 输入参数,点击提交按钮,若正在提交,则显示如下图
5. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
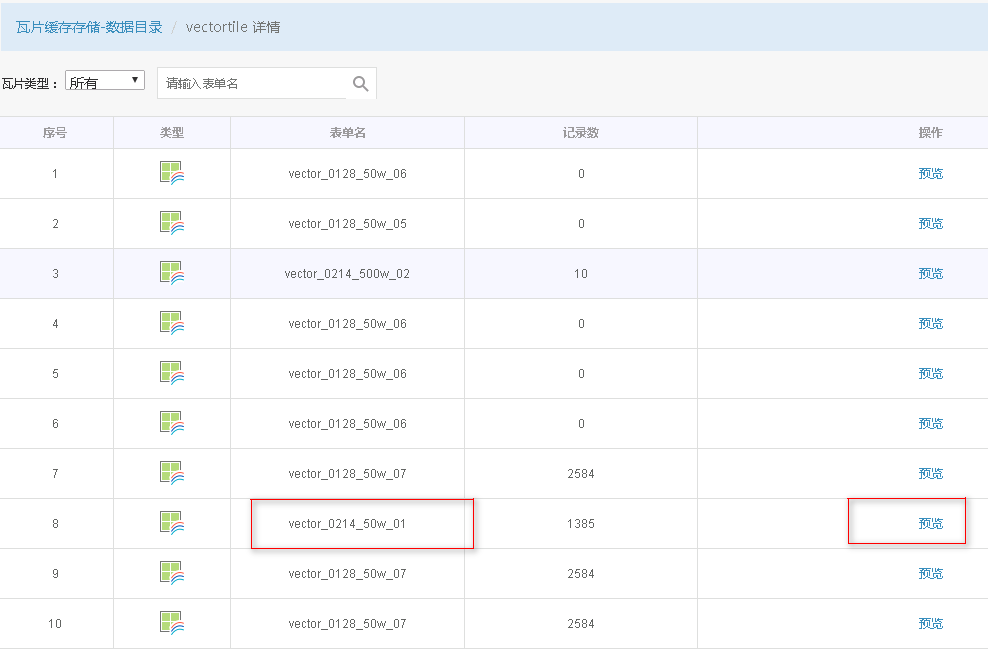
6. 待正常执行完后,则可在DataStore中切片数据存储目录中看到结果,并可在线浏览切片数据,如下图所示。

参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 图层地址列表 | 被裁剪图层的存储地址 | http://192.168.96.101:9091/datastore/rest/ dataset/pg/service/show/show/JBNT_MKT | 是 | 1.如果是单图层,可在右侧的目录树中进行选择。 2.如果是多图层,只能手动填写,图层地址之间用逗号分隔。 |
| 图层名列表 | 自定义矢量瓦片图层名 | 株洲市,长沙市,岳阳市 | 是 | 如果是多图层,图层名之间用逗号分隔。 |
| 保留字段 | 矢量瓦片中需要保留的字段 | mpshape,地类名称,地类编码 | 是 | |
| 起始层级 | 适量瓦片的起始层级 | 5 | 是 | |
| 结束层级 | 适量瓦片的截止层级 | 15 | 是 | |
| 保留拓扑关系 | 是否启用保留拓扑关系算法 | true | 是 | 选择ture,裁剪结果会尽量保持相邻图元之间的拓扑关系,但是会加大裁剪过程耗时。 |
| 化简方式 | 化简策略选择 | MaxPointInline | 是 | MaxPointInline通过每条边设置最少保留点来防止化简过度。Distance通过距离阈值来进行化简 |
| 比例 | 最少保留点设置,此处百分比为总点数的百分比。 | 50 | 是 | |
| 距离 | 距离设置,通过距离阈值来进化简 | 12 | 是 | |
| 分区数 | 裁剪任务spark并行度 | 10 | 是 | |
| 输出图层URL | 结果数据存储路径 | mongo://19218.96.101:40000/vectortile/xxx | 是 | 支持mongo和pg-XL |
| 裁剪模式 | 裁剪模式 | 目前有批量裁剪和逐层裁剪可供选择 | 是 | 批量裁剪耗电脑资源大,相对耗时短,建议数据量小时启用 |
# 空间分析服务
# 叠加分析
# 功能说明
该功能主要对两个矢量数据进行叠加分析,并依据条件,可对叠加结果进行汇总统计,形成结果。
# 操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击叠加分析任务,进入参数配置页面,参数见下说明,如下图所示:
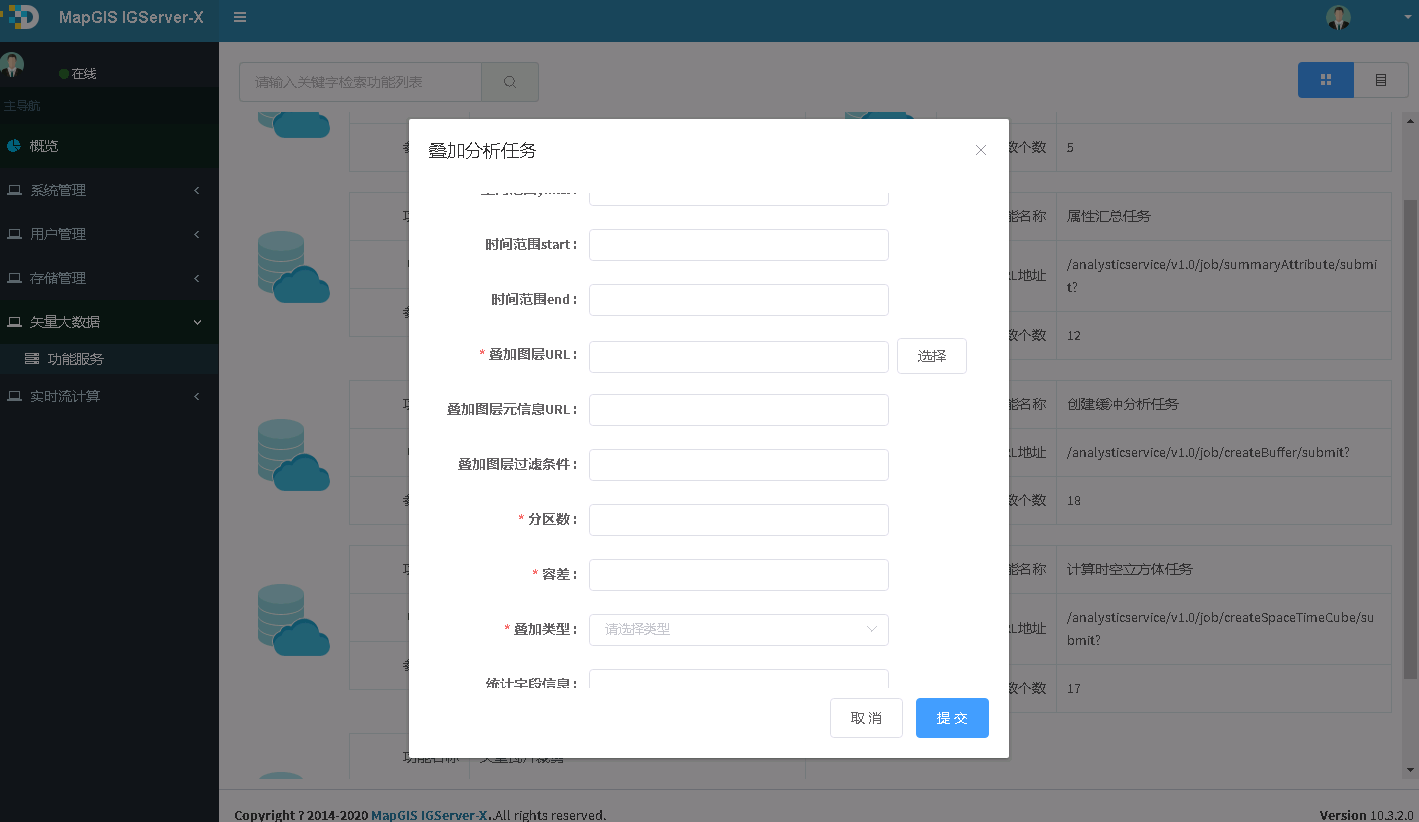
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。
5. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/DLTB_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 叠加图层URL | 被叠加数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/JBNT_MKT | 是 | |
| 叠加图层元信息URL | 叠加数据字段映射文件 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | ||
| 叠加图层过滤条件 | 叠加数据属性过滤条件 | 地类名称=大坪村 | 否 | |
| 分区数 | Spark任务并行度 | 10 | 是 | |
| 容差 | 拓扑重建容差 | 0.0001 | 是 | |
| 叠加类型 | 支持交、并、差 | Interset | 是 | |
| 统计字段信息 | 结果汇总设置 | [ { "field":"trip_distance", "statisticTypes":["mean","sum"] }, { "field":"speed", "statisticTypes":["mean", "count"] } ] | 否 | 如果不想直接返回叠加结果,而是想对叠加结果进行统计,返回统计结果,此参数可以设置需要统计的字段和统计类型 |
| 计算引擎 | 支持spark、pg | Spark | 是 | |
| 结果图层URL | 目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 | 是 |
# 缓冲分析
# 功能说明
该功能主要用于创建可进一步分析的区域,适用于两个图层,对其中一个图层进行缓冲,在区域里对另一个图层进行汇总分析。
# 操作说明
1. MapGIS 10各产品线文档整理:根据产品管理部提供文档模板,调整Desktop操作手册格式。进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击创建缓冲任务,进入参数配置页面,参数见下说明,如下图所示:

3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。

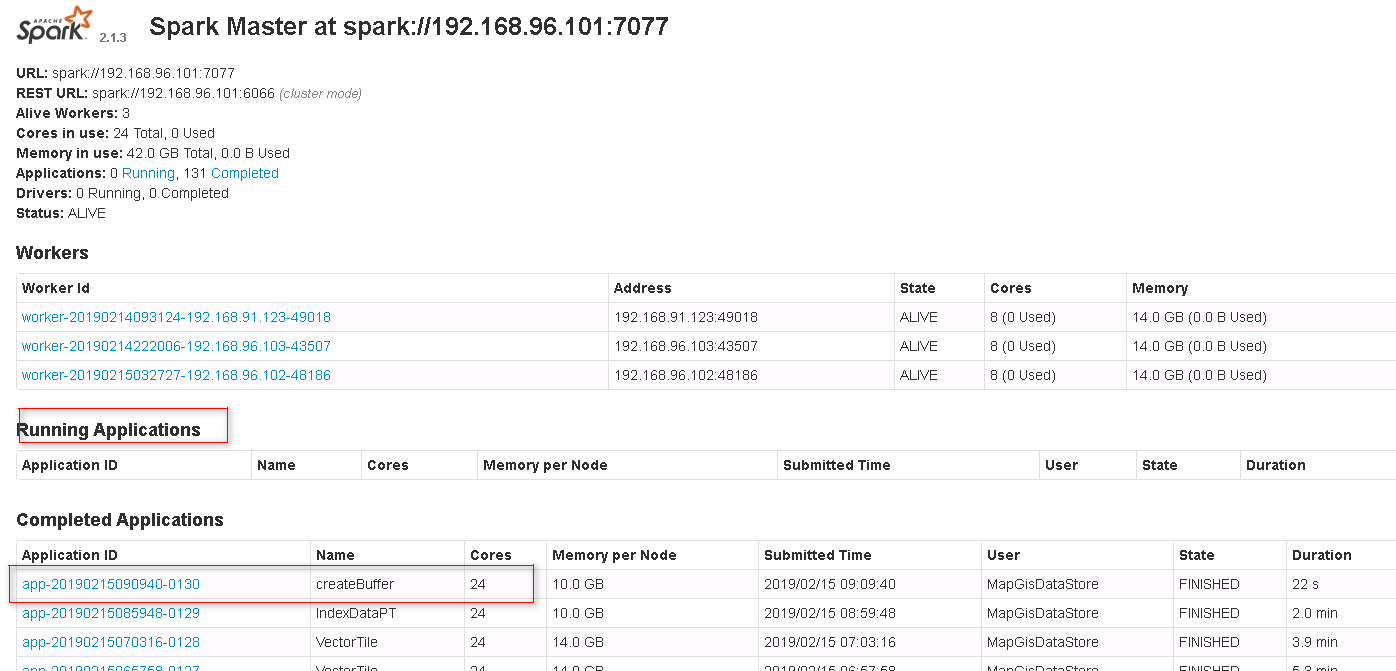
5. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。
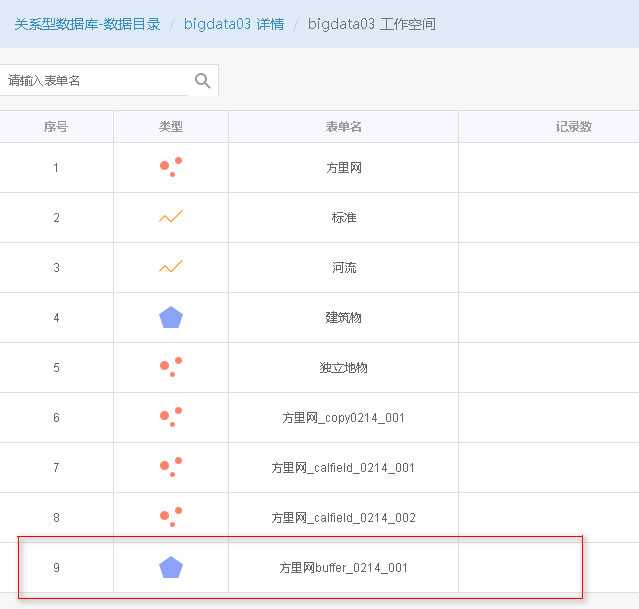
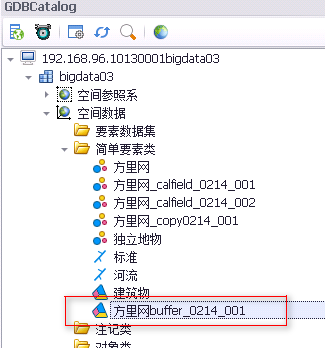
场景:如果问题是学校1英里范围内有哪些建筑物?答案可以通过在学校周围创建1英里缓冲区并将缓冲区与包含建筑物覆盖物的图层重叠来找到。最终的结果是学校1英里范围内的一层建筑物。
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/DLTB_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 缓冲距离 | 缓冲距离,和缓冲距离单位为一组参数,与缓冲表达式为二选一参数 | 10 | 否 | |
| 缓冲距离单位 | 缓冲距离单位 | meter(米)、kilometer(千米)、none(数据单位) | 否 | |
| 缓冲计算表达式 | 缓冲计算表达式 | fld0*(fld1+20)-fld2 | 否 | |
| 缓冲类型 | 缓冲类型 | flat(平头)、round(圆头) | 否 | |
| 缓冲选项 | 缓冲选项 | all(聚合所有)、list(聚合相交部分)、none(不做处理) | 是 | 目前只支持none、all |
| 保留字段数组 | 保留字段数组,用逗号分隔 | fld1,fld2 | 否 | |
| 是否合并为多部分 | 几何是否合并为多部分,当保留字段选项all、list时生效 | 勾选是和否 | 否 | |
| 统计字段信息 | 统计字段信息,当保留字段选项all、list时生效,值型字段支持 count, min,max,mean,sum, variance,stddev,range 等 | [ { "field":"trip_distance", "statisticTypes":["mean","sum"] }, { "field":"speed", "statisticTypes":["mean", "count"] } ] | 否 | |
| 结果图层URL | 目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 hdfs://192.168.96.101:9000/nyc | 是 |
# 数据汇总服务
# 属性汇总分析
# 功能说明
该功能对输入数据汇总和统计计算数据数值,支持个数、最大值、最小值、均值、方差、中值等统计量的计算。
# 操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击属性汇总任务,进入参数配置页面,参数见下说明,如下图所示:
提示:
预览界面中名称为准,暂不可以平台桌面中看到的字段名为准,因为平台看到的有可能是大写,数据库可能是小写字母
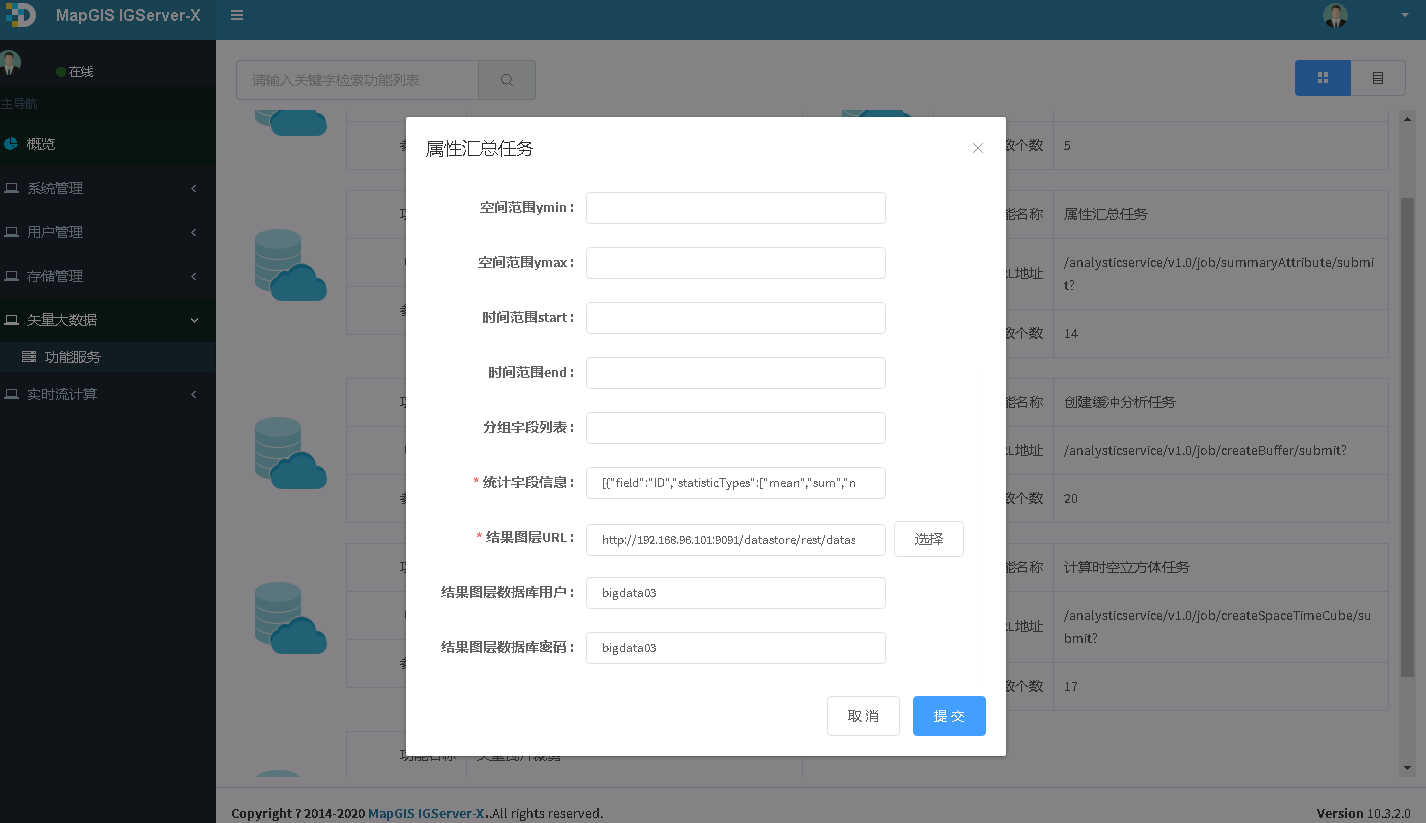
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。

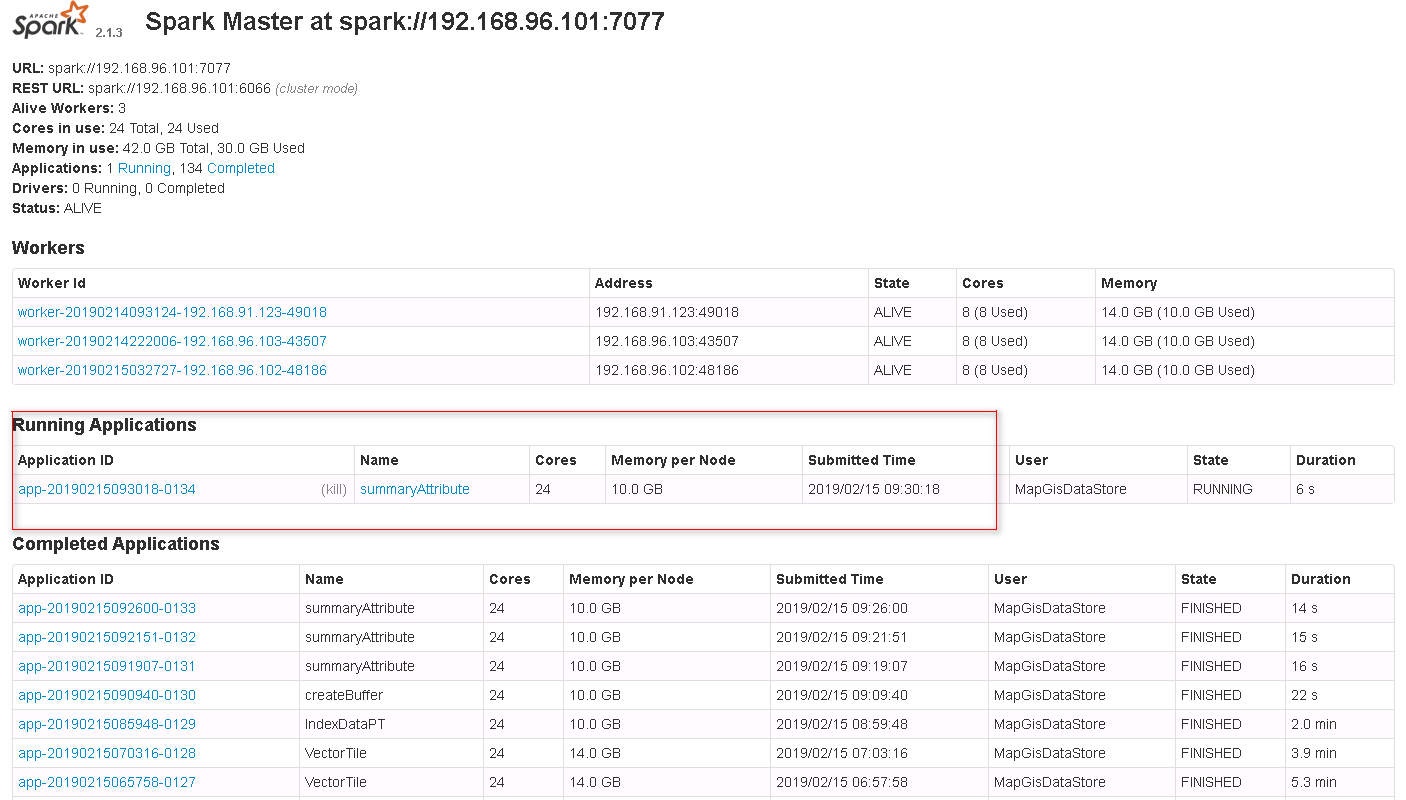
5. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。
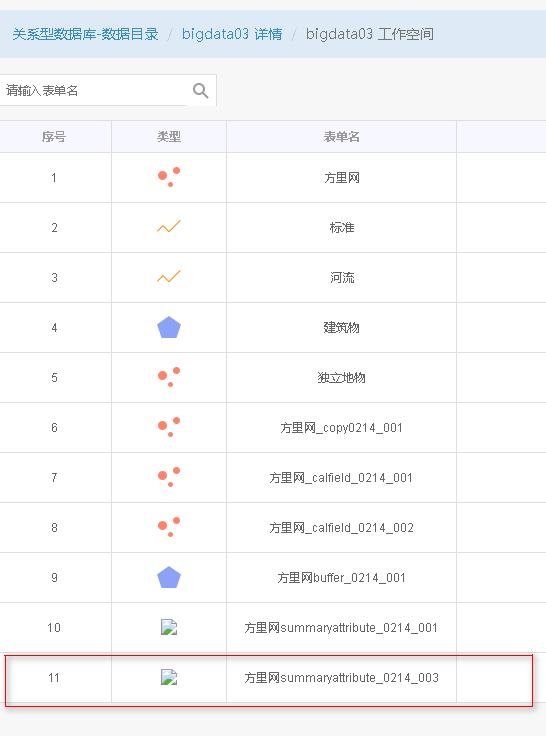
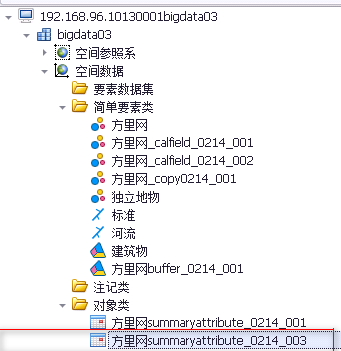
参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/JBNT_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 分组字段列表 | 分组字段列表,不选则全部合为一组 | 否 | ||
| 统计字段信息 | 统计字段信息 ,数值型字段支持 count,min,max,mean,sum,variance, stddev,range | [ { "field":"trip_distance", "statisticTypes":["mean","sum"] }, { "field":"speed", "statisticTypes":["mean", "count"] } ] | 是 | |
| 结果图层URL | 目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 | 是 |
# 格网聚合点要素
# 功能说明
该功能又称为点聚合,使用点要素图层和区要素图层,输入的区要素图层可以来自多边形图层,也可以是工具运行时计算的正方形或六边形区域格网。系统首先确定哪些点位于每个指定区域内,在确定了点和区的空间关系之后,将计算该区所有点的统计数据并分配给该地区,作为其基本属性。最基本的统计数据是该地区内点数的数量,但也可以获得其他统计数据,该功能主要用于对点数据进行聚合统计。
# 操作说明
1. 进入"矢量大数据"菜单中"功能服务"页面,在该页面默认会列出所有可用的分析功能服务,当输入关键字后,可筛选出与关键字相关的分析功能服务。
2. 点击格网聚合点要素任务,进入参数配置页面,参数见下说明,如下图所示:
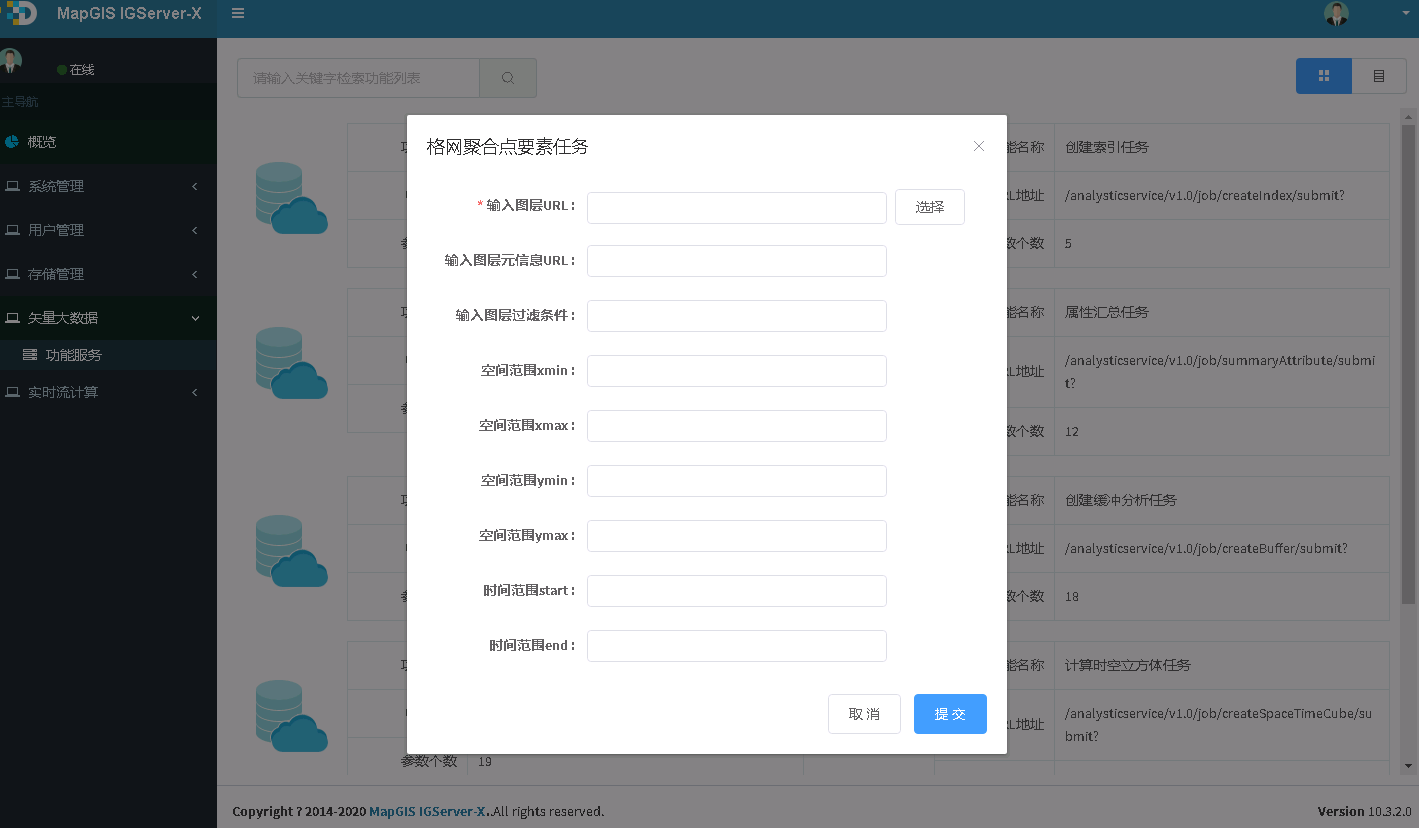
3. 输入参数,点击提交按钮,若正在提交,则显示如下图
4. 任务正常提交完,则显示任务ID,提示如下图,点击查看,进入Spark监控页面查看任务执行情况。

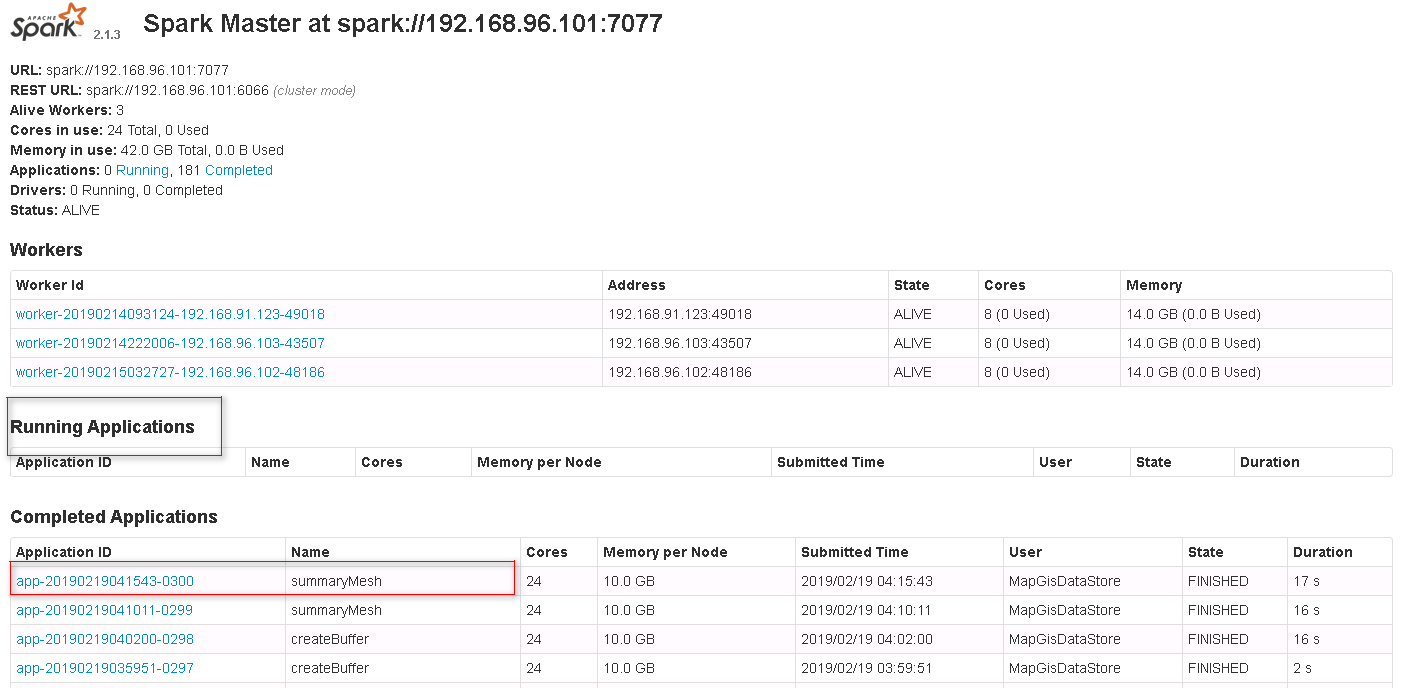
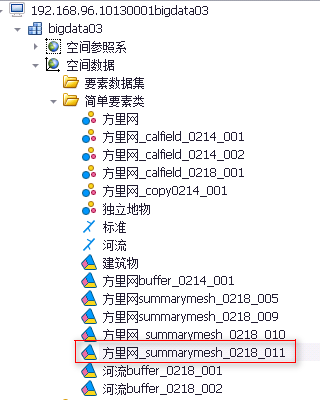
5. 待正常执行完后,则可在DataStore目录中看到结果,亦可在平台桌面中看到结果图层数据,如下图所示[左:DataStore 右:平台桌面]。

参数说明
参数名称 | 参数说明 | 参数示例 | 是否必填 | 备注 |
|---|---|---|---|---|
| 输入图层URL | 源数据存储地址 | http://192.168.96.101:9091/datastore/rest/dataset/ pg/service/show/show/DLTB_MKT | 是 | |
| 输入图层元信息URL | 源数据字段映射文件 | 否 | 如果源数据在pg中,该参数不需要设置,如果源数据在hdfs中,为了防止字段类型自动识别出错,最好通过此参数提供字段映射 | |
| 图层过滤条件 | 源数据属性过滤条件 | Mparea>10000 | 否 | |
| 空间范围xmin | 源数据空间过滤条件 | 113.4 | 否 | |
| 空间范围xmax | 源数据空间过滤条件 | 114.3 | 否 | |
| 空间范围ymin | 源数据空间过滤条件 | 27.5 | 否 | |
| 空间范围ymax | 源数据空间过滤条件 | 28.8 | 否 | |
| 时间范围start | 源数据时间过滤条件 | 2018-01-18 00:00:00 | 否 | |
| 时间范围end | 源数据时间过滤条件 | 2018-01-18 13:00:00 | 否 | |
| 网格类型 | 格网类型 | 方形、六边形,给值: hexagon,square | 否 | |
| 格网边长 | 格网边长 | 1000 | 否 | |
| 格网边长单位 | 格网边长单位 | meter(米)、kilometer(千米)、none(数据单位) | 否 | |
| 聚合图层URL | 聚合区图层地址 | hdfs://192.168.96.101:9000/mapgisanalystserver/ nyc/trip_data_1.csv | 否 | |
| 聚合图层元信息URL | 聚合区图层元信息json的URL地址,支持hdfs、http | hdfs://192.168.96.101:9000/mapgisanalystserver/ datasetschema.json | 否 | |
| 聚合图层过滤条件 | 聚合区图层属性过滤条件 | speed>100 | 否 | |
| 时间间隔 | 时间间隔 | 10 | 否 | |
| 时间间隔单位 | 时间间隔单位 | second,minute,hour,day, week,month,year | 否 | |
| 时间步长 | 时间步长 | 否 | ||
| 时间步长单位 | 时间步长单位 | second,minute,hour,day, week,month,year | 否 | |
| 时间标准起点 | 时间标准起点,默认 0 | 1970-01-0108:00:00 | 否 | |
| 统计字段信息 | 统计字段信息 , 数值型字段支持 count,min,max,mean,sum,variance, stddev,range 等 | [{"field":"trip_distance","statisticTypes":["mean","sum"]},{"field":"speed","statisticTypes":["mean", "count"]}] | 否 | |
| 结果图层URL | 目的地址 | pg://mapgis@mapgis/192.168.81.223:5432/postgis/ summarymesh_hexgon_96_101_001 | 是 |